

Kira PESHKOV, Klim PESHKOV
La traduction automatique du discours juridique : est-elle fiable ?
Kira Peshkov
Docteure en études slaves de l’Université d’Aix-Marseille
Traductrice Experte agréée par la Cour de cassation
Experte près la Cour d’appel d’Aix-en-Provence
kirapeskov@gmail.com
Klim Peshkov
Traducteur, Spécialiste en traitement automatique des langues
klim.peshkov@gmail.com
Résumé
La traduction automatique devient de plus en plus performante ce qui, en principe, est censé économiser le temps et les ressources du traducteur. Une traduction automatique du discours juridique ne nécessitant pas de phase de post-édition importante est-elle déjà possible ? Le présent article explore la possibilité d’utilisation de DeepL, l’un des meilleurs outils de traduction automatique, pour l’aide à la traduction du discours juridique. L’analyse linguistique de la traduction du discours juridictionnel montrera les différents types d’erreur de DeepL et leur fréquence. Dans la conclusion de l’article nous mettrons en garde les traducteurs et ceux qui utilisent la traduction automatique dans un contexte juridique.
Abstract
Machine translation of legal discourse: is it reliable?
Machine translation is becoming more and more effective, and one could hypothesize that it should bring about the economy of translator’s time and effort. Is machine translation of legal discourse which does not require substantial post-editing efforts already possible? The paper explores the possibility of usage of one of the best machine translation tools DeepL in the task of assisting in legal discourse translation. Linguistic analysis of judicial discourse translation will show different types of errors of DeepL and their frequency. The paper’s conclusion warns translators and those who use machine translation in a legal context.
Introduction
La traduction automatique (par la suite : TA) devient de plus en plus performante, ce qui est censé économiser le temps et les ressources du traducteur, d’autant plus que les traductions juridiques sont souvent demandées en urgence, les délais de traduction étant soumis à la procédure légale. Dans ces conditions, le recours à la traduction automatique permet de gagner du temps. Mais avec quel résultat dans la langue-cible ?
La traduction du discours juridique pose des problèmes tant aux niveaux terminologique et notionnel qu’au niveau culturel. Le présent article interroge la possibilité d’utiliser l’un des meilleurs outils de TA, DeepL, basé sur les réseaux neuronaux, pour aider à la traduction du discours juridique, et la nécessité d’une phase de post-édition (révision par un traducteur humain).
L’analyse linguistique montrera les différents types d’erreurs les plus fréquentes de DeepL dans la traduction franco-russe du discours juridique. Ainsi, connaissant toutes les contraintes de la traduction juridique dans ces deux langues, nous évaluerons l’efficacité que présente DeepL dans la tâche de production d’une traduction fidèle.
La conclusion répondra à la question de la pertinence d’utilisation de ce traducteur automatique pour assurer la qualité de traduction nécessaire au bon fonctionnement de la justice dans le contexte national et international. Cette analyse pourra servir aux traducteurs et autres utilisateurs de DeepL dans le contexte juridique et, également, aider les concepteurs à améliorer les performances des systèmes de TA.
Nous nous arrêterons plus spécifiquement sur la traduction du discours juridictionnel. Dans le contexte judiciaire, la traduction peut intervenir dans tous les types de procédures : civile, pénale, administrative et sociale. Elle remplit deux fonctions bien distinctes : la première est de servir d’outil de communication pour l’autorité judiciaire et, la seconde, d’être une garantie procédurale pour le justiciable qui ne comprend pas la langue de la procédure. Dans le premier cas, la traduction participe à la coopération judiciaire, en permettant le dialogue entre les autorités judiciaires des États. Elle permet également aux magistrats et autres professionnels d’accéder au contenu d’un document rédigé en langue étrangère. Dans le second cas, la traduction permet au justiciable qui ne comprend pas la langue de la procédure de bénéficier d’un procès équitable (MONJEAN-DECAUDIN 2010).
Le Décret n° 2013-958 du 25 octobre 2013 confirme l’importance de la traduction pour la jurisprudence française. Son objet est de mettre en œuvre le droit à l’interprétation et à la traduction dans le cadre des procédures pénales. La personne suspectée ou poursuivie ne comprenant pas la langue française a droit, dans une langue qu’elle comprend et jusqu’au terme de la procédure, à l’assistance d’un interprète et à la traduction des pièces essentielles à l’exercice de sa défense pour garantir le caractère équitable du procès. La traduction écrite en matière pénale est devenue donc une partie intégrante des procédures judiciaires et un droit à part entière (BRANNAN 2016).
Dans ce contexte, la qualité de la traduction, les enjeux et les effets juridiques qu’elle produit sont très importants non seulement pour les parties du procès mais également pour la société tout entière (GÉMAR 2011 : 9). C’est pourquoi « le droit veille, au nom de la sécurité juridique, à la fidélité des traductions destinées aux tribunaux, à l’administration et aux personnes privées : si le texte traduit a, en soi, pour finalité de créer des droits, l’exigence de fidélité est particulièrement demandée » (IRIMIA 2016 : 332).
1. Cas décrits de l’utilisation de la TA dans le monde juridique
La TA étant devenue ubiquitaire dans tous les domaines, nous nous sommes intéressés à la question de l’existence des cas décrits de l’utilisation de la TA dans le monde juridique et de son acceptation normative.
Il apparaît que certaines institutions ont émis des directives concernant l’utilisation de la TA (VIEIRA et al. 2021). Par exemple, au Canada, la Commission de l’immigration et du statut de réfugié désigne la TA comme type de traduction non conforme. Il y a eu des cas de rejet de documents par un tribunal canadien pour cette même raison (X v Re 2013). Le tribunal d’État américain du Nouveau-Mexique a ordonné que les sorties de la TA non corrigées ne pouvaient pas être utilisées pour les documents à destination officielle (CHÁVEZ 2008). Un tribunal de district de Californie a indiqué le manque de fiabilité des documents traduits par la TA et présentés comme preuves (Novelty Textile, Inc. v. Windsor Fashions, Inc. 2013).
Nous pouvons aussi citer des cas flagrants d’utilisation de la traduction automatique par des agents non-informés de risques, comme l’utilisation de la TA par un avocat dans la communication avec le client (Vasquez v. US 2019) et l’utilisation de la TA par le tribunal lui-même (Super Express Usa Publishing Corp. v. Spring Publishing Corp. 2017).
Cette liste n’est pas exhaustive, mais elle nous montre que la question de la traduction du discours juridique par la TA est d’actualité depuis au moins une décennie.
2. Pourquoi DeepL ?
DeepL est l’un des moteurs de TA les plus populaires, avec 254 millions de visites en avril 2023, ce qui est moins que Google Translate qui compte 702 millions de visites, cependant ceux qui ont testé DeepL ont tendance à le préférer (COLDEWAY, LARDINOIS 2017). Les langues traduites par DeepL sont au nombre de 30, ce qui représente 800 paires de langues possibles. Et il est à noter que 45 % des visiteurs du service proviennent de 5 pays : Japon, États-Unis, France, Allemagne et Chine[1].
Une comparaison entre DeepL, à base de réseau de neurones, et le moteur de traduction automatique statistique incorporant des mémoires de traducteur, Microsoft Translator Hub, a été effectuée dans la tâche de traduction de l’allemand vers le français. Les auteurs concluent, vu les résultats des évaluations automatique et manuelle, que DeepL a donné de meilleurs résultats : la sortie produite par DeepL a été plus rapide à post-éditer et a nécessité moins de corrections. (VOLKART et al. 2018).
DeepL a également été comparé à d’autres systèmes neuronaux. Google Translate, comme DeepL, est un système à base de réseau de neurones, qui utilise aussi des éléments de l’architecture Transformer, mais en la combinant avec une architecture « réseau de neurones récurrents » (RNN pour recurrent neural network en anglais), plus précisément LSTM (long short-term memory). En le comparant avec DeepL dans la tâche de traduction des expressions multi-mots, c’est ce dernier qui s’est révélé plus performant (ESPERANÇA-RODIER, FRANKOWSKI 2021). DeepL a été évalué et désigné comme plus performant par rapport à Google Translate et Microsoft Translator dans la traduction des métadonnées des images ukiyo-e dans la traduction du japonais vers l’anglais (SONG et al. 2020). Google Translate et DeepL ont été également évalués pour la paire de langues slovène-anglais avec des résultats non concluants : Google Translate a été meilleur dans l’une des tâches et DeepL dans une autre (ŽAGAR, ROBNIK-ŠIKONJA 2022).
Sur son site, DeepL a une page spéciale destinée aux professionnels du droit où il promet « une IA traductionnelle sûre pour les services juridiques » pour des textes juridiques complexes, comme les contrats. Il se positionne en tant que « traducteur automatique le plus précis et le plus sûr au monde », « un outil de choix pour les avocats, les cabinets juridiques et les organismes gouvernementaux du monde entier » (Une IA traductionnelle sûre pour les services juridiques)[2].
Une étude explorant la qualité de la traduction juridique entre l’italien et l’allemand par DeepL a montré que ses résultats étaient prometteurs (HEISS, SOFFRITTI 2018).
Les résultats de ces études, les promesses de DeepL ainsi que la réputation de cet outil parmi les utilisateurs francophones et russophones nous ont poussés à analyser ses performances.
3. La technologie qui sous-tend DeepL
DeepL est une technologie de traduction automatique développée par la société allemande DeepL GmbH à Cologne. La traduction est générée par un super-ordinateur de 5.1 pétaflops se trouvant en Islande et alimenté par l’énergie hydroélectrique.
Il n’y a pas beaucoup d’informations sur les détails techniques de son fonctionnement. L’entreprise ne publie pas d’articles. La seule source officielle est une présentation sur son site : How does DeepL work ?[3]
Le système DeepL repose sur des réseaux neuronaux d’apprentissage profond, et plus précisément, sur une combinaison des types de réseau neuronal appelé réseau neuronal convolutif (en anglais : CNN, convolutional neural network) (COLDEWAY, LARDINOIS 2017) et l’architecture Transformer.
Le modèle Transformer, comme type d’architecture de réseau neuronal, a été introduit dans un article de recherche de Google en 2017 (VASWANI et al. 2017). Il a été conçu pour surmonter certaines limitations des modèles précédents, telles que le problème de dépendance à long terme qui rendait difficile la traduction de phrases longues de manière précise.
La technologie de DeepL intègre des mécanismes d’attention adoptés du modèle Transformer, qui aident le réseau à se concentrer sur les parties les plus pertinentes du texte source (How does DeepL work ?). Ce modèle utilise « l’attention à plusieurs têtes » (multi-headed self-attention) qui s’occupe des liens de chaque mot de la phrase avec les autres et permet au contexte de déterminer quel sens du mot choisir. Cela donne au système la possibilité de désambiguïser les mots à partir du contexte. Par exemple, dans la phrase La fée a jeté un sort avec sa baguette, le sens du mot baguette est influencé par la fée et un sort.
De plus, l’entreprise a développé une méthode propriétaire pour optimiser l’architecture et les hyperparamètres du réseau neuronal, ce qui, selon elle, contribue à améliorer encore davantage la qualité des traductions.
Le réseau neuronal DeepL est entraîné sur de vastes quantités de textes bilingues, y compris la base de textes parallèles Linguee, comprenant des documents officiels, des articles de presse et d’autres textes provenant de diverses sources, en utilisant une technique appelée apprentissage supervisé. Pendant l’entraînement, le réseau apprend à identifier des motifs et des relations entre les mots et les phrases dans les langues source et cible, et utilise ces motifs pour générer des traductions de haute qualité.
4. Évaluation de la TA
Il existe des propositions d’évaluer la qualité de la TA automatiquement en la comparant avec la traduction humaine à l’aide des métriques de similitude (PAPINENI et al. 2002). Néanmoins, les évaluations automatiques rencontrent des problèmes connus. Par exemple, elles ne prennent pas en compte la gravité des erreurs et la variabilité de la traduction, contrairement à l’évaluation humaine (CALLISON-BURCH et al. 2006). Notre étude présente une évaluation humaine qualitative.
Des travaux récents abordent l’évaluation de la TA dans le domaine juridique. Nombre d’auteurs notent que l’utilisation des sorties de TA en l’état est impossible, une phase de post-édition est nécessaire (BISIANI 2022 ; BRACCHI 2024 ; KHALFALLAH 2021 ; VOLCLAIR 2023) et peut se révéler plus compliquée que la traduction manuelle (PLAVINSKAYA 2022). Dans une de ces études l’auteur relate une conclusion basée sur l’expérience de 12 traducteurs professionnels : ils ne croient pas que la TA de DeepL soit d’une utilité quelconque dans la traduction des courriers d’avocats (VOLCLAIR 2023). Certaines études ont souligné les manquements des systèmes de TA dans la traduction des termes juridiques (BISIANI 2022 ; BRACCHI 2024). La provenance des données d’entraînement d’un système à réseau neuronal détermine le terme que le système choisit comme équivalent dans la traduction : étant entraîné en majeure partie sur des textes de niveau international, DeepL tend à choisir les termes propres à ce genre de texte même dans le contexte national (BISIANI 2022).
Nous avons pris comme objet d’analyse le discours juridictionnel afin de tester les performances de DeepL dans la traduction juridique franco-russe. Nous avons fait ce choix parce que ce genre de discours est régulièrement traduit par les traducteurs experts près les Cours d’appel et la Cour de cassation.
5. Le discours juridictionnel
Le discours juridique, reconnu comme spécifique par tous les spécialistes, n’est pas homogène. Cornu (2005) souligne l’extrême diversité des discours du droit. Gémar (1995 : 115-116) précise que le terme générique « langage du droit » recouvre plusieurs langages particuliers qui forment une typologie essentielle des divers discours juridiques possibles. Cette diversité apparaît au travers de différentes terminologies ou classifications de genres de discours juridiques proposées (PESHKOV 2012 : 24-26).
Pour caractériser le discours juridictionnel nous présentons ci-dessous un tableau qui donne une vision globale du genre de discours étudié du point de vue communicatif et fonctionnel. Nous y avons tenu compte des messages juridiques essentiels énumérés par Cornu (2005 : 233). Le tableau précise l’émetteur du discours (Cour, tribunal), le récepteur (sujets du procès), le but du discours, à savoir la réalisation et la création du droit, l’énoncé principal qui est l’énoncé décisoire et les textes où le discours est réalisé : décisions, arrêts, ordonnances, jugements etc. Ce tableau est commun aux deux langues étudiées.

Tableau : Discours juridictionnel
Cornu consacre tout un chapitre de son ouvrage fondamental de jurilinguistique à la complexité du discours juridictionnel. Il souligne, entre autres, que :
Dans le discours du juge, viennent aussi nécessairement au contact l’un de l’autre, le fait et le droit, le particulier et le général, le concret et l’abstrait. Le jugement est le lieu de leur rencontre […]. Son caractère composite ne met pas seulement à rude épreuve la concision de l’énoncé. La nécessité de se justifier en fait et en droit y introduit plusieurs langages, celui du fait, celui de la preuve, celui du droit et celui de la logique (CORNU 2005 : 334 ; souligné par Cornu).
Dans sa décision, le juge affirme sa connaissance du fait et du droit. Les références au fait et au droit ne sont examinées que dans leurs conséquences linguistiques. On voit apparaître dans le texte du jugement « toutes les opérations intellectuelles qui sont attendues du juge, dans le processus de sa démonstration et qui font, de la partie démonstrative du jugement un discours extraordinairement diversifié » (CORNU 2005 : 344 ; souligné par Cornu). Les procédés référentiels dans le discours juridictionnel ont été spécialement étudiés par Sobieszewska qui caractérise ce discours comme un « type particulier de discours juridique qui s’érige traditionnellement en parangon de la clarté et de la précision judiciaire » (SOBIESZEWSKA 2014 : 2899).
Ainsi, la description des faits, des preuves, des avis, chaque détail du jugement, chaque personne mentionnée, chaque qualification juridique, c’est-à-dire chaque composant linguistique de ce discours a, sur le plan lexical, grammatical ou syntaxique, un sens juridique précis et nécessaire pour la compréhension du jugement et pour la réalisation du droit. En ce sens, l’importance de la qualité de la traduction ne peut pas être sous-estimée.
6. Classification des erreurs faites par DeepL
Pour apprécier la qualité de la traduction du discours juridictionnel par DeepL, nous avons constitué un corpus de décisions de justice françaises dont des jugements correctionnels, ordonnances, arrêts de la Cour d’appel et de la Cour de cassation. Les jugements ont été traduits en russe par DeepL Pro. Ensuite, toutes les erreurs ont été enregistrées, regroupées et quantifiées.
L’analyse linguistique a démontré que les erreurs relevées peuvent être regroupées entre six grandes catégories. Classification des erreurs faites par DeepL :
I. Lexicales
- I.1 lexèmes de la langue courante
- I.2 termes juridiques simples et complexes (syntagmes terminologiques)
- a) emploi d’un synonyme de la langue courante
- b) choix d’un mauvais sens d’un lexème polysémique
- c) choix d’un mauvais homonyme
- d) traduction mot à mot des termes complexes
- e) substitution d’un terme par un lexème de la langue courante de sens proche
- f) emploi d’un terme de sens proche
- g) substitution d’un terme par un hyperonyme
- h) correspondances difficilement explicables
- I.3 collocations juridiques
- I.4 noms propres
II. Grammaticales
- II.1 déclinaison
- II.2 temps
- II.3 régime verbal
- II.4 accord en nombre et en genre
- II.5 préposition mal traduite
- II.6 possessifs
III. Syntaxiques
IV. Omissions
V. Séquences non-traduites
VI. Ajouts
Pour illustrer cette classification, nous présenterons quelques exemples d’erreurs dans des tableaux précisant le texte source, la traduction erronée de DeepL, le texte corrigé et, là où c’est possible, la traduction inversée (back translation – la « rétro-traduction » des sorties de DeepL en russe vers la langue source, le français) à l’intention des lecteurs ne maîtrisant pas la langue russe.
I. Erreurs lexicales
I.1 Lexèmes de la langue courante
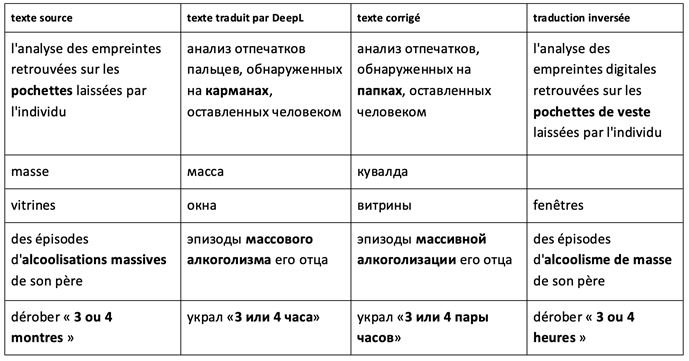
L’analyse de ces exemples montre que la TA se trompe dans le choix d’équivalents de lexèmes polysémiques comme, ici, masse et pochette. Dans les exemples comme alcoolisation et montre l’équivalent choisi par DeepL est un lexème de la même famille morphologique dans la langue d’arrivée, mais avec un sens inapproprié. Le lexème cible peut être lié par un sème au lexème source (verre dans l’exemple où DeepL a traduit vitrine comme fenêtre).
Le post-éditeur de la décision de justice peut soit voir une incohérence ou même une absurdité dans le texte cible et les corriger manuellement, soit ne pas les remarquer et être induit en erreur.
I.2. Terme juridique simple ou complexe
L’emploi erroné d’un terme est apparu comme le type d’erreur prédominant. C’est pourquoi nous nous y arrêterons de manière plus détaillée.
Le terme juridique est à la base du discours juridique et de l’activité même du droit. Il est indéniable que la maîtrise de la terminologie est l’une des conditions essentielles d’une bonne traduction juridique. Pour être fiable, la TA doit être capable de rendre fidèlement la notion juridique dans le texte cible. Ce n’est manifestement pas le cas de DeepL qui présente des erreurs dites « terminologiques » plus ou moins graves.
En se penchant sur les erreurs terminologiques, nous pouvons distinguer les mécanismes les plus fréquents d’apparition de ces erreurs comme suit.
- a) Emploi d’un synonyme de la langue courante
Nous avons constaté de nombreux cas dans lesquels la TA remplace le terme juridique dans le texte source par un lexème du langage commun dans le texte cible. Ce fait rend le texte cible dépourvu de sens juridique et le prive d’une information importante, ce qui est incompatible avec les normes d’une traduction juridique de qualité.

- b) Choix d’un mauvais sens d’un lexème polysémique
Voici quelques exemples où la TA choisit pour un lexème polysémique un équivalent erroné en contexte juridique. Par exemple, au lieu de réquisition du ministère public, DeepL emploie un autre sens du même lexème à savoir « Procédé par lequel l’autorité (civile ou militaire) exige la fourniture d’objets mobiliers, la jouissance de biens immobiliers ou la prestation de certains services pour assurer le fonctionnement du service public » (TLFi[4]) au lieu de « Demande faite en justice ou dans des formes prescrites » (TLFi). Et c’est dans ce sens erroné que le terme est traduit en russe pour donner dans le texte cible реквизиции au lieu de требования прокурора.
Un exemple d’erreur qui résulte en absurdité concerne le terme parquet : DeepL emploie en russe le lexème qui signifie assemblage de lames de bois au lieu de ministère public.
Les termes information ainsi que faits ont été traduits en russe dans leurs sens non juridiques.

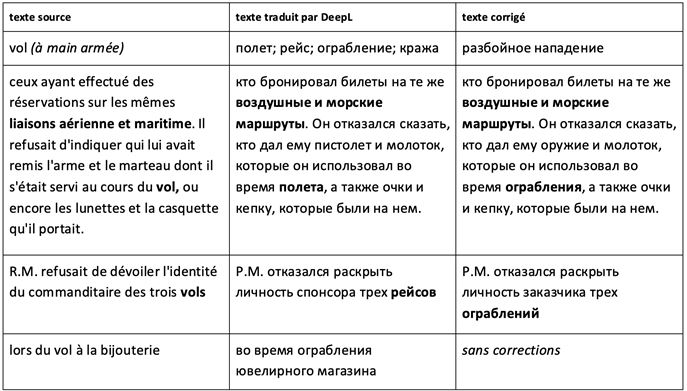
- c) Choix d’un mauvais homonyme
Nous présentons ici l’exemple du lexème vol qui a été souvent mal traduit dans l’un des arrêts du corpus. DeepL a choisi le vol dans le sens de « Fait d’être transporté en l’air d’un point à un autre en s’y maintenant en suspension » au lieu de l’« Action de s’emparer frauduleusement de ce qui appartient matériellement à autrui » (TLFi). Sachant que la décision portait sur le vol à main armée, le terme vol a été fréquemment employé dans l’arrêt.
En examinant le deuxième exemple ci-dessous, nous supposons que DeepL prend en compte le contexte d’une ou peut-être de quelques phrases. Dans ce cas, il ferait mieux d’appliquer l’auto-attention à l’échelle du document, et le vol serait probablement pris dans le sens juridique dans tout le document.
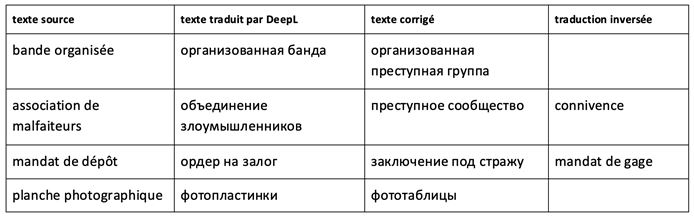
- d) Traduction mot à mot des termes complexes
Le terme complexe qui désigne un concept juridique doit être traduit comme une unité. Or, DeepL propose souvent une traduction mot à mot des composants du syntagme terminologique sans chercher un équivalent du terme dans le système terminologique de la langue d’arrivée. Ce sont des erreurs inadmissibles qui changent les propos du juge. Par exemple, le terme mandat de dépôt a été traduit mot à mot : le lexème dépôt a été traduit comme залог ce qui a donné en russe ордер на залог (mandat de gage). Le terme mandat de dépôt, très fréquent dans le discours juridictionnel, est important pour décrire le déroulement des procédures pénales, il signifie « ordre donné au chef d’un établissement pénitentiaire […] de recevoir et détenir, selon le cas, soit une personne mise en examen […], soit un prévenu ou un accusée » (GUILLIEN et al. 2005 : 393).
Les autres exemples montrent également que le concept traduit est représenté dans le texte d’arrivée par une unité non terminologique, ce qui vide la décision de justice en russe de son sens juridique et entraîne des imprécisions, voire des fautes graves de compréhension. C’est le cas des termes bandes organisée et planche photographique traduits littéralement. Leurs traductions inversées seraient identiques au texte source, c’est pourquoi nous ne les montrons pas.
Plus loin, les erreurs représentent des sous-types d’erreurs (de e à g) regroupées sous l’étiquette de «traductions imprécises» qui incluent des erreurs moins graves pour la compréhension. Le sens des termes employés est proche de celui de la langue source, mais les termes dans la langue cible manquent de précision, ce qui peut avoir des conséquences négatives pour la procédure judiciaire. Ainsi, co-mis en examen n’a pas le même sens juridique que coauteur et le terme saisine n’est pas équivalent à renvoi. Nous présentons ci-dessous les différentes façons dont cette imprécision se manifeste.
- e) Substitution d’un terme par un lexème de la langue courante de sens proche
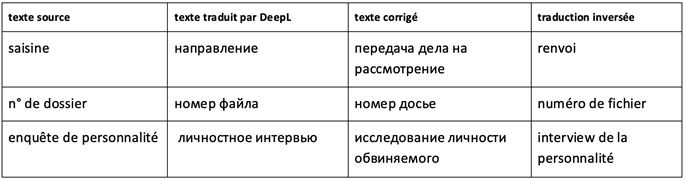
- f) Emploi d’un terme de sens proche
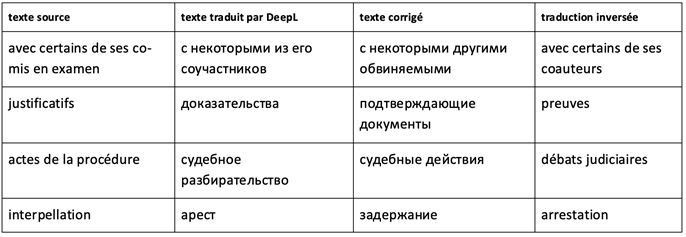
- g) substitution d’un terme par un hyperonyme
L’emploi d’un hyperonyme au lieu d’un terme spécifique équivalent diminue la qualité et la précision de la traduction.
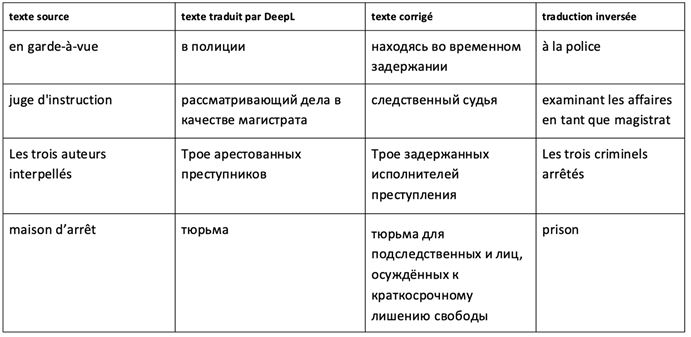
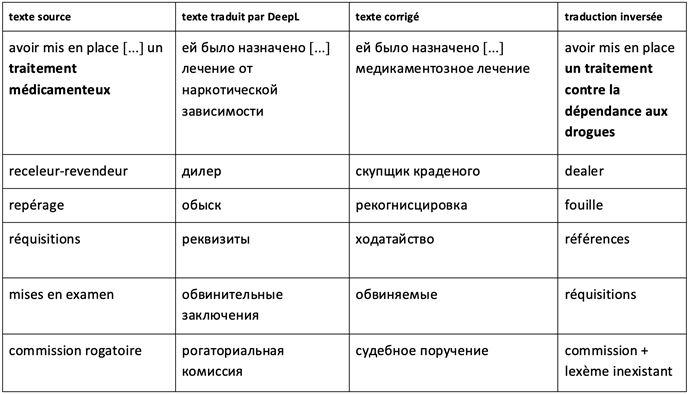
- h) Correspondances difficilement explicables
Certaines substitutions de termes sont tellement improbables qu’elles s’apparentent à des « hallucinations[5] ». Le système semble inventer des sens qui n’existent pas dans la source, par exemple, traitement médicamenteux est traduit beaucoup plus spécifiquement par traitement contre la dépendance aux drogues. Le système peut même inventer des mots inexistants dans la langue cible, comme avec la commission rogatoire, traduit par рогаториальная комиссия. Ces erreurs ne sont pas évidentes à repérer sans examen attentif de l’original, mais le sens du texte est considérablement distordu. Pour identifier ces erreurs il faut être conscient que le système est capable d’en faire.
Nous avons également observé la variation de traduction incorrecte d’un terme. Dans un même texte, la TA peut proposer un équivalent tantôt correct, tantôt incorrect d’un terme ou plusieurs variantes incorrectes uniquement, par exemple :
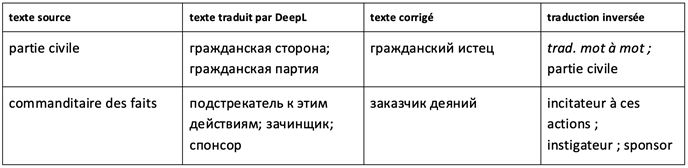
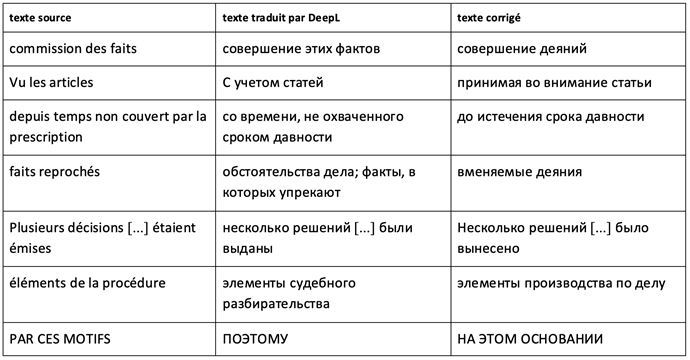
I.3 Collocations juridiques
Une collocation spécialisée peut être définie comme une occurrence lexicale privilégiée par l’usage d’éléments linguistiques entretenant une relation syntaxique de subordination ou de coordination dans le discours spécialisé. Les collocations juridiques ont des traits caractéristiques par rapport aux collocations de la langue générale et jouent un rôle important dans le discours juridique. Elles relient un texte au domaine spécialisé, remplissant une fonction de cohérence du discours, et contribuent à la nomination des processus et de faits complexes. Étant partie intégrante du système de la langue, ces unités se définissent par un nombre de particularités usuelles, syntaxiques et sémantiques. Le discours du droit abonde de collocations sans lesquelles il est difficile de représenter un texte juridique et, en l’espèce, une décision de justice.
Nous distinguons trois types de collocations juridiques : terminologiques, non terminologiques et de termes (PESHKOV 2013)[6]. Dans la traduction réalisée par DeepL, on trouve un nombre de traductions erronées de tous les types de collocations. Voici quelques exemples :
I.4 Erreurs de traduction des noms propres
Nous avons constaté que les noms propres (noms de personnes, d’entreprises, toponymes) sont souvent transcrits avec des erreurs.
Avec notre expérience d’enseignement universitaire de la langue juridique et de la traduction juridique français-russe, nous pouvons constater que certaines erreurs lexicales sont le fait tant d’apprenants non natifs que de locuteurs natifs qui ne maîtrisent pas la langue juridique, à savoir, qu’ils essayent de traduire mot à mot un terme complexe ou une collocation juridique, d’employer un synonyme de la langue courante au lieu d’un terme juridique. En revanche, il est difficile d’imaginer l’emploi par les apprenants d’un homonyme qui ne correspond même pas au contexte, comme l’a fait DeepL.
II: Erreurs grammaticales
De nombreuses erreurs grammaticales ont été relevées dans les traductions réalisées par DeepL. Plus spécifiquement, il s’agit de fautes de déclinaison, de temps, de régime verbal, d’accord en genre et en nombre, de préposition mal traduite et de possessifs. Voici quelques exemples :
II.1 Déclinaison

II.2 Temps

II.3 Régime verbal

II.4 Accord en nombre et en genre

II.5 Préposition

II.6 Possessifs
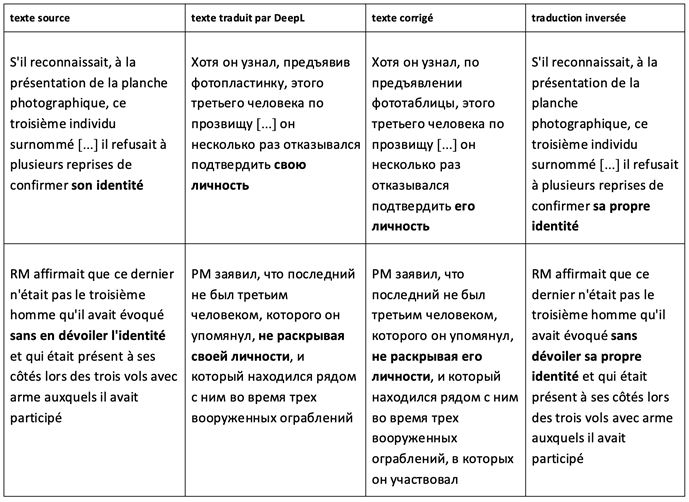
On observe de nombreuses erreurs dans l’emploi des possessifs. Les possessifs свой et его sont souvent confondus. À noter que свой s’emploie uniquement lorsque le possesseur est le sujet de la proposition. Si le possesseur n’est pas le sujet de proposition, le possessif comporte une indication de personne. Dans les exemples qui suivent, c’est le possessif его (troisième personne du masculin singulier) qui doit être employé pour préserver le sens de la phrase.
III. Erreurs de syntaxe
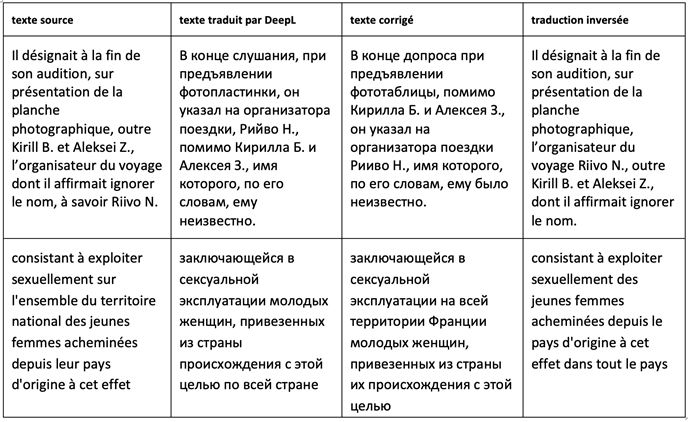
Certaines analyses de la TA mentionnent que les erreurs de syntaxe sont courantes dans les sorties de tels systèmes (PLAVINSKAYA 2022 : 5). Le discours juridique est connu pour sa syntaxe complexe qui entraîne des erreurs rendant la traduction difficilement compréhensible. Ainsi, dans le premier exemple cité de la traduction faite par DeepL, la personne interrogée affirme ignorer plutôt le nom d’Aleksei Z. que le nom de Riivo N. En outre, Kirill B. et Aleksei Z. sont devenus dans le texte d’arrivée des organisateurs de voyage. Dans le deuxième exemple, la mention de l’ensemble du territoire national comme le terrain d’exploitation sexuelle des jeunes femmes acheminées depuis leur pays d’origine disparait et la phrase devient incompréhensible.
IV. Omissions
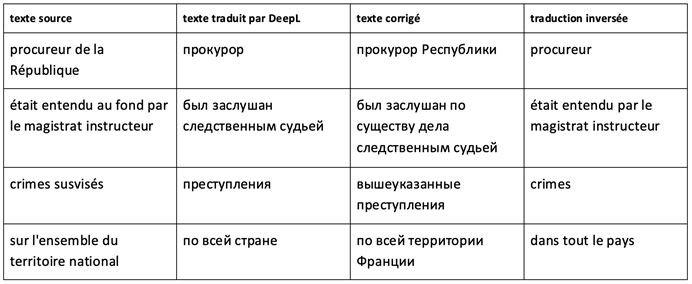
Nous avons remarqué que DeepL peut omettre une partie du terme complexe, d’une collocation ou un lexème de la langue courante. Une partie d’information reste ainsi manquante dans le texte cible.
V. Séquences non-traduites
Noms de personnes, de lieux, d’entreprises laissés en français dans le texte d’arrivée.
VI. Ajouts
L’ajout représente un autre type d’erreur difficilement détectable à la lecture du texte d’arrivée et peut être qualifié comme une « hallucination ». Dans la traduction apparaissent des informations complètement absentes dans le texte source[7]. Qui peut penser que la TA ajoute de l’information inexistante dans la décision de justice et « embellit » le texte traduit ? Nous avons, par exemple, remarqué l’emploi récurrent du sigle РФ, signifiant « Fédération de Russie », après quasiment chaque mention des Codes français. Il est tout de même évident pour un lecteur averti que la personne, même si elle est de nationalité russe, ne sera pas jugée en France selon la législation de la Fédération de Russie.
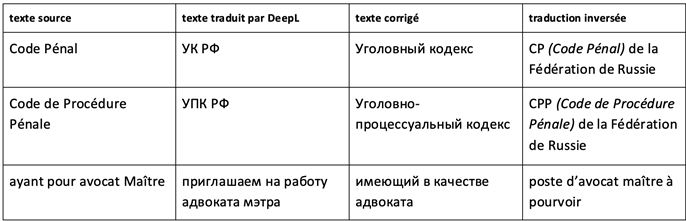
VII. Contresens
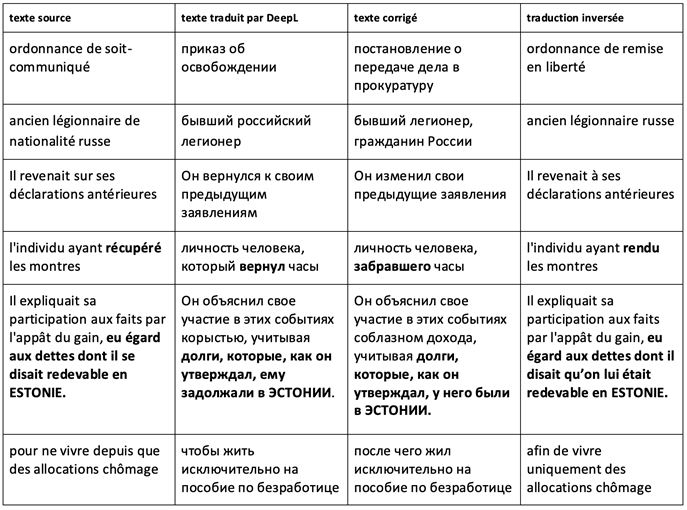
Tous les types d’erreurs que nous avons examinés plus haut peuvent entraîner, comme nous l’avons vu, une distorsion ou omettre une information nécessaire dans la décision de justice traduite. Ces erreurs vont jusqu’aux contresens, ce qui est très dangereux, car elles changent complètement le sens sans être apparentes, et ne sont détectables qu’en prenant en considération le texte source. C’est-à-dire qu’à la simple lecture du texte d’arrivée, elles peuvent être ignorées par le post-éditeur et, bien évidemment, par un utilisateur qui croit sans réserve aux promesses de DeepL sur la qualité de la traduction juridique. Voici quelques exemples de contresens dans des traductions d’arrêts :
VIII. Aperçu quantitatif
La figure 1. présente les pourcentages par type d’erreur dans notre corpus. Les plus fréquentes sont les erreurs terminologiques. Soulignons ici qu’au niveau international et interculturel, la question de l’équivalence terminologique, mais aussi de la précision des termes et des concepts qu’ils désignent, est fondamentale.
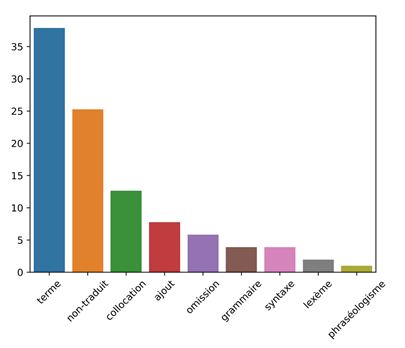
Figure 1. Pourcentages par type d’erreur
En deuxième place viennent les séquences non-traduites qui sont, pour la plupart, des noms propres (entités nommées) donnés dans l’alphabet de la langue source. Ensuite nous voyons les erreurs dans les collocations juridiques, toutes les données sur lesquelles DeepL a été entraîné ne lui ont pas permis d’apprendre à résoudre parfaitement cette difficulté.
Avant de conclure pour donner un aperçu du travail de post-édition, nous présentons deux pages type de la traduction d’une ordonnance traduite par DeepL avec les erreurs soulignées (voir Annexes 1 et 2).
Nous constatons que DeepL a réussi de nombreuses phrases. En même temps, le nombre d’erreurs à identifier et à corriger est considérable. Une post-édition importante est donc nécessaire.
La post-édition (en anglais PEMT, post-editing machine translation) est un processus de correction des sorties de la traduction automatique par un humain. Le but de la post-édition n’est pas nécessairement de produire un équivalent parfait du texte, comme il serait traduit par un traducteur humain, mais de rendre un résultat compréhensible en langue cible en utilisant le minimum de temps et d’efforts (SHEVCHUK, NIKIFOROVA 2021). Cependant dans certains cas, et c’est le cas de la traduction des décisions de justice, la traduction doit être précise. La qualité humaine est donc exigée, ce qui fait que la qualification du post-éditeur doit être de haut niveau. Il peut être, par exemple, un expert jurilinguiste qui est informé des types d’erreurs que peut commettre la TA.
Conclusion
À l’heure actuelle, le traducteur automatique ne peut pas assurer la qualité de traduction nécessaire au bon fonctionnement de la justice dans le contexte national et international sans intervention humaine. Il peut tout de même être un outil d’un traducteur spécialisé qui pourrait assurer une post-édition importante. Le traducteur de texte juridique ne peut pas savoir en avance combien d’erreurs va faire la TA et il est tout à fait possible qu’il passe autant de temps à post-éditer la traduction que de traduire, en fonction de la complexité du texte. S’il choisit la post-édition, il doit être conscient du comportement de la TA, que nous avons discuté ici. Il doit porter une attention particulière aux détails et il doit maîtriser la terminologie du domaine en question.
Pour les personnes pour lesquelles la TA est la seule manière d’accéder au sens du texte, c’est la conscience des risques de la gravité des erreurs et des éventuels contresens qui détermine l’utilité et la sûreté de son utilisation.
Références bibliographiques
BISIANI, Francesca, « Les “minorités” en Italie et en France. L’impact de la traduction automatique sur la détermination des concepts juridiques », Traduire. Revue française de la traduction, n. 246, 2022, p. 65‑76.
BRACCHI, Enrica, « Traduction juridique à l’aide de DeepL et selon une approche juritraductologique : retour sur expérience », Recherche et pratiques pédagogiques en langues, n. 42 (2), 2023. https://journals.openedition.org/apliut/11086
BRANNAN, James, « L’article 3 de la directive 2010/64/UE : la traduction écrite en matière pénale devient un droit à part entière », Éla. Études de linguistique appliquée, n. 183 (3), 2016, p. 281‑295.
CALLISON-BURCH, Chris et al., « Re-evaluating the role of BLEU in machine translation research », 11th conference of the european chapter of the association for computational linguistics, 2006, p. 249‑256. https://aclanthology.org/E06-1032.pdf
CHÁVEZ, Edward L., « New Mexico’s success with non-English speaking jurors », Journal of Court Innovation, n. 1, 2008, p. 303‑328.
COLDEWAY, Devin, LARDINOIS, Frederic, « DeepL Schools Other Online Translators with Clever Machine Learning », TechCrunch.com, 2017. https://techcrunch.com/2017/08/29/deepl-schools-other-online-translators-with-clever-machine-learning/
CORNU, Gérard, Linguistique juridique, 3e éd, Paris, Montchrestien, 2005.
ESPERANÇA-RODIER, Emmanuelle, FRANKOWSKI, Damian, « DeepL vs Google Translate : Who’s the Best at Translating MWEs from French into Polish ? A Multidisciplinary Approach to Corpora Creation and Quality Translation of MWEs », Translating and the Computer, n. 43, 2021. https://hal.science/hal-03779450
GÉMAR, Jean-Claude, « Aux sources de la “jurilinguistique” : texte juridique, langues et cultures », Revue française de linguistique appliquée, n. 16 (1), 2011, p. 9‑16.
GÉMAR, Jean-Claude, Traduire ou l’art d’interpréter 2. Langue, droit et société : éléments de jurilinguistique. Application, Québec, Presses de l’Université de Québec, 1995.
GUILLIEN, Raymond, VINCENT, Jean, Lexique des termes juridiques, Paris, Dalloz, 2005.
HEISS, Christine, SOFFRITTI, Marcello, « DeepL Traduttore e didattica della traduzione dall’italiano in tedesco. Alcune valutazioni preliminari », InTRAlinea. Special Issue : Translation and Interpreting for Language Learners (TAIL), n. 20, 2018. http://www.intralinea.org/specials/article/2294
Irimia, Dorina, « Pour une nouvelle branche de droit ? La traduction juridique, du droit au langage », Éla. Études de linguistique appliquée, n. 183 (3), 2016, p. 329‑341.
KHALFALLAH, Nejmeddine, « La traduction juridique et les systèmes de traduction automatique », EKB Journal Management, n. 106 (71), 2021, p. 1‑14.
LEE, Katherine et al., « Hallucinations in neural machine translation », 2018, https://scholar.google.com/scholar?cluster=13047383023392116047&hl=fr&as_sdt=0,5
MONJEAN-DECAUDIN, Sylvie, La traduction du droit dans la procédure judiciaire : contribution à l’étude de la linguistique juridique, Thèse de doctorat, Paris 10, 2010. https://www.theses.fr/2010PA100102
Novelty Textile, Inc. v. Windsor Fashions, Inc. Case No. CV 12-05602 DDP (MANx), 20 mars 2013.
PAPINENI, Kishore et al., « Bleu : a method for automatic evaluation of machine translation », Proceedings of the 40th annual meeting of the Association for Computational Linguistics, 2002, p. 311‑318. https://aclanthology.org/P02-1040.pdf
PESHKOV, Kira, Le discours juridique en russe et en français : une approche typologique, Thèse de doctorat, Université d’Aix-Marseille, 2012. https://tel.archives-ouvertes.fr/tel-00997016
PESHKOV, Kira, « Collocations dans le discours du droit russe », in KOR CHAHINE, Irina, ZAREMBA, Charles (éds.), Travaux de slavistique. Actes du VI e congrès de la Slavic Linguistics Society, Langues et langages, n. 25, 2013, p. 175-186.
PLAVINSKAYA, T. = Плавинская, Т. А., « О некоторых особенностях постредактирования машинного перевода юридического документа », XIV Всероссийская научно-практическая конференция Диалог языков и культур : лингвистические и лингводидактические аспекты, Тверь, 2022.
SHEVCHUK, Ekaterina = Шевчук, Екатерина Владимировна, NIKIFOROVA, Janna = Никифорова, Жанна « Постредактирование и типичные ошибки в автоматизированном переводе научно-публицистических текстов », Вопросы методики преподавания в вузе, n. 39 (10), 2021, p. 46‑54.
SOBIESZEWSKA, Marta, « Procédés référentiels dans le discours juridictionnel : Cas des arrêts de la cour de cassation », Congrès Mondial de Linguistique Française, 2014, p. 2899‑2916.
SONG, Yuting et al., « A preliminary attempt to evaluate machine translations of ukiyo-e metadata records », Digital Libraries at Times of Massive Societal Transition: 22nd International Conference on Asia-Pacific Digital Libraries, Kyoto, Japan, November 30–December 1, 2020, Springer, 2020, p. 262‑268.
Super Express Usa Publishing Corp. v. Spring Publishing Corp. 13-cv-2814 (DLI)(JO), 24 mars 2017.
Vasquez v. US. 3:16-cv-2623-D-BN, 30 janvier 2019.
VIEIRA, Lucas Nunes et al., « Understanding the societal impacts of machine translation : a critical review of the literature on medical and legal use cases », Information, Communication & Society, n. 11 (24), 2021, p. 1515‑1532.
VASWANI, Ashish et al., « Attention is all you need », Advances in neural information processing systems, n. 30, 2017.
https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
VOLCLAIR, Alain, « DeepL résout-il les conflits ? Bio-traduire et post-éditer les courriers d’avocats de l’italien en français », Journal of Data Mining & Digital Humanities, n. 6, 2023. https://doi.org/10.46298/jdmdh.9299
VOLKART, Lise et al., « Statistical vs. Neural Machine Translation : A Comparison of MTH and DeepL at Swiss Post’s Language Service », Proceedings of the 40th Conference Translating and the Computer, 2018, p. 145‑150.
X v Re. CarswellNat 10832, No. TB3-01748, 2013.
ŽAGAR, Ales, ROBNIK-ŠIKONJA Marko, « Slovene SuperGLUE Benchmark : Translation and Evaluation », in CALZOLARIE Nicoletta et al. (éds.), Proceedings of the Thirteenth Language Resources and Evaluation Conference, Marseille, 2022. https://arxiv.org/pdf/2202.04994
Sitographie
How does DeepL work? https://www.deepl.com/en/blog/how-does-deepl-work, accédé le 02.04.2024
http://similarweb.com, accédé le 03.04.2023
TLFi http://atilf.atilf.fr/tlfv3.htm accédé le 03.03.2024
Une IA traductionnelle sûre pour les services juridiques https://www.deepl.com/fr/deepl-for-legal-teams, accedé le 02.04.2024
Annexe 1

Annexe 2

[1] http://similarweb.com, accédé le 03.04.2023.
[2] https://www.deepl.com/fr/deepl-for-legal-teams, accedé le 02.04.2024.
[3] https://www.deepl.com/en/blog/how-does-deepl-work, accédé le 02.04.2024.
[4] http://atilf.atilf.fr/tlfv3.htm, accédé le 03.03.2024.
[5] Une « hallucination » est une traduction hautement pathologique, produite par l’IA, qui n’est pas liée au texte source (LEE et al. 2018).
[6] Le trait distinctif des collocations non terminologiques est l’absence de terme dans leur composition, elles servent à uniformiser les textes du droit et sont en quelque sorte des marqueurs du discours juridique. Les collocations terminologiques comprennent deux parties : la base et le collocatif. La base est représentée par un terme juridique, le collocatif n’est pas un terme. Les collocations de termes se composent de deux ou plusieurs termes juridiques qui peuvent à leur tour être simples ou composés. Dans les collocations de termes les deux parties sont équivalentes, de telle sorte qu’il est difficile, voire impossible de définir une base et un collocatif.
[7] À différencier avec la distorsion de sens de l’unité lexicale présente dans le texte source (voire I.2 h).
Per citare questo articolo:
Kira PESHKOV, Klim PESHKOV, « La traduction automatique du discours juridique : est-elle fiable ? », Repères DoRiF, n. 32 Le droit e(s)t la langue, DoRiF Università, Roma, aprile 2025.
ISSN 2281-3020
![]()
Quest’opera è distribuita con Licenza Creative Commons Attribuzione – Non commerciale – Non opere derivate 3.0 Italia.