
Nicoletta ARMENTANO
La traduction automatique inclusive dans le cadre institutionnel européen: une approche neuronale sous contraintes
Nicoletta Armentano
Università degli Studi di Perugia
nicoletta.armentano@unipg.it
Résumé
Cet article interroge la nature situationnelle du concept d’inclusion à travers l’un de ses terrains d’actualisation les plus sensibles : la traduction interlinguale de l’écriture inclusive. En prenant appui sur le Guide du Parlement européen (2018) ainsi que sur les Lignes Directrices du Conseil de l’Europe (2024) en matière d’écriture inclusive, nous analyserons les tensions entre exigences d’un langage respectueux de l’égalité de genre, les contraintes propres aux textes institutionnels et les spécificités du multilinguisme européen à la sensibilité culturelle et grammaticale hétérogène. Une analyse linguistique outillée sera menée afin d’évaluer dans quelle mesure une traduction inclusive automatique est envisageable en contexte institutionnel, et si les technologies linguistiques sont capables de faire converger normativité, contraintes contextuelles et logiques traductives.
Abstract
This article explores the situated nature of the concept of inclusion through one of its most sensitive fields of actualization: inclusive writing and its interlingual translation. Drawing on the European Parliament’s Gender-Neutral Language Guidelines (2018) and the Council of Europe’s Guidelines for the use of language as a driver of inclusivity (2024), we analyze the tensions between gender-sensitive language requirements, institutional constraints, and the culturally and grammatically diverse multilingualism of the European context. A tool-assisted linguistic analysis is undertaken to determine whether institutional automatic inclusive translation is possible and to what extent linguistic technologies can reconcile normativity, institutional constraints, and translation logic.
1. Introduction
Qu’il soit question d’un effort démocratique (GUERRINI 2008), d’un changement de paradigme éducatif (PRUD’HOMME et al. 2016), d’un impératif normatif d’accessibilité (LARROUY 2006), d’un horizon communautaire et participatif tel que défini par les politiques européennes récentes (cf. Horizon Europe 2021-2027), ou encore d’un « concept horizon » au sens sociologique (PAUGAM 1996), le terme d’inclusion s’impose aujourd’hui comme un vecteur transversal de transformation sociale, politique, institutionnelle et langagière.
Loin d’être figée[1], cette notion fait l’objet d’actualisations multiples et continues, perceptibles dans des mesures concrètes – allant de l’adoption d’un langage plus inclusif à la suppression des barrières d’ordre architectural, mental et numérique, jusqu’à la pleine reconnaissance des libertés individuelles et identités plurielles. La notion d’inclusion témoigne, ainsi, d’une nature multidimensionnelle (et d’une polyphonie conceptuelle) qui engage à la fois les structures collectives et les subjectivités.
Or, cette pluralité d’expressions et d’usages souligne également la dépendance étroite du concept d’inclusion aux contextes concrets de mise en œuvre, qu’ils soient fortement institutionnalisés ou davantage personnels et identitaires. Par conséquent, dans le même mouvement où le concept d’inclusion s’impose comme incontournable, il devient essentiel d’interroger cette nature situationnelle, en particulier à travers les modalités langagières par lesquelles elle se traduit et se matérialise dans les textes, les dispositifs et les discours. Car le langage, en tant que formidable vecteur d’idées et de représentations (GALISSON 1988 ; AMOSSY, HERSCHBERG PIERROT 1997), est à même de faire émerger, de visibiliser, d’amplifier ou, au contraire, de masquer certains aspects du réel, comme l’inclusivité (LO NOSTRO, MINERVINI 2024). C’est dans ce cadre que la question du langage inclusif – envisagé comme incarnation opératoire du concept dans la sphère discursive (HADDAD 2016) – s’est imposé à notre réflexion, à la fois comme enjeu politique et espace d’observation proprement linguistique (VIENNOT 2017 ; RABATEL, ROSIER 2019), notamment dans un contexte européen multiculturel et multilingue où les processus de traduction ajoutent une couche de complexité mais aussi de potentialité interprétative du concept.
Dans les pages qui suivent, nous nous attachons à analyser les contraintes structurelles propres aux environnements institutionnels – en l’occurrence, le Conseil de l’Europe et le Parlement européen – face à l’usage de l’écriture inclusive[2] et à sa traduction interlinguale. Cette dernière nous semble constituer un terrain d’observation particulièrement éclairant des tensions entre l’expression de la diversité (RAUS, TONTI 2025) – notamment de genre, les spécificités culturelles des communautés discursives de chaque État membre et les traditions grammaticales nationales.
Notre démarche repose sur une analyse linguistique outillée à partir de deux ressources officielles de l’Union européenne : le guide du Parlement européen (2018) – dans les versions française (Usage d’un langage neutre du point de vue du genre) et italienne (La neutralità di genere nel linguaggio usato al Parlamento europeo) – et les lignes directrices du Conseil de l’Europe (2024), dans la seule version en français (Pour l’utilisation d’un langage vecteur d’inclusivité). Dans un premier temps, nous présenterons ces documents et leur structure interne. Dans un second temps, un mini-corpus de phrases élaborées spécifiquement selon ces recommandations servira de base à une expérimentation située au croisement de la traductologie, des humanités numériques et des études de genre. Celle-ci visera à évaluer dans quelle mesure une traduction inclusive automatique, conforme aux directives mentionnées, est réalisable. Trois hypothèses de recherche guident notre démarche :
- a. En l’absence de données d’entraînement pertinentes, les systèmes de traduction automatique neuronale (désormais TAN) reproduisent les formes genrées majoritaires ;
- b. Les TAN tendent à appliquer des stratégies inclusives génériques ;
- c. Les TAN manifestent une capacité limitée à intégrer la dimension situationnelle, ce qui compromet la portée inclusive des traductions ;
Nous mettrons à l’épreuve ces hypothèses en testant la sensibilité de trois moteurs de traduction neuronale (DeepL, Google traduction, Yandex). Cette étude entend contribuer à une réflexion critique sur les conditions linguistiques de mise en œuvre des principes d’écriture inclusive, à l’intersection des recommandations institutionnelles, du genre discursif des textes officiels et des TAN.
2. Pratiques traductives automatiques neuronales et genre
Afin de préciser la pertinence de notre approche, qui articule le concept d’inclusion aux systèmes de traduction automatique neuronale dans la perspective des recommandations européennes sur l’écriture inclusive, disons d’emblée que les choix terminologiques en apparence anodins – comme l’usage du masculin générique ou l’effacement des identités non binaires – contribuent à reconduire des représentations genrées et inégalitaires, comme l’ont démontré les travaux de linguistes féministes (MICHARD 2003 ; YAGUELLO 1992 ; VIENNOT 2014), des spécialistes des théories féministes de la traduction (VON FLOTOW 2011) ou encore les études sur la traduction dans un perspective de genre (AMADORI 2022). Renouer avec les logiques de la langue, rompre avec l’élitisme imposé à la langue, innover la langue de manière créative et attester que « la primauté du masculin n’est ni intuitive, ni naturelle, ni nécessaire » (LESSARD, ZACCOUR 2017 : 9) figurent parmi les réponses possibles à cet état de fait.
Cette inégalité devient d’autant plus visible à l’ère des technologies langagières, où les systèmes de traduction automatique neuronale reproduisent et parfois amplifient les biais de genre présents dans leurs données d’entraînement. De nombreuses études ont ainsi documenté la présence de nombreux stéréotypes de genre dans les traductions (BAEZA-YATES 2018 ; BERGER 2019 ; CRIADO-PEREZ 2019 ; EMERY 2021 ; SAVOLDI 2025 ; WISNIEWSKI et al. 2021). Prates (2020) et Sofo (2022), par exemple, ont mis en lumière une tendance à masculiniser certaines professions, sous l’influence de la structure syntaxique ou par la présence d’adjectifs connotés ; Stanovsky (2019) a observé une meilleure précision lorsqu’un amalgame entre profession et genre est explicité, ce qui souligne l’asymétrie de traitement des genres. D’autres travaux ont tenté de proposer des pistes d’atténuation, qu’il s’agisse d’ajouts lexicaux (COSTA-JUSSA 2019), de recours à des noms propres pour réduire l’ambiguïté, ou encore d’identification de structures problématiques (MONTI 2017). Par ailleurs, Marzi (2022) insiste sur la nécessité d’un encadrement critique de ces technologies et Cadwell (2016) sur le rôle fondamental des traducteurs humains dans la phase de post-édition.
Ainsi, à la lumière de ces réflexions, il apparaît essentiel de réaffirmer que l’inclusion ne constitue ni un mot d’ordre abstrait, ni un principe uniforme. Elle ne prend sens que lorsqu’elle est pensée dans des contextes discursifs situés, au croisement des contraintes culturelles, matérielles et (extra)langagières. C’est pourquoi nous proposons d’aborder la question de l’inclusion dans une perspective de genre dans les systèmes de traduction automatique à partir d’un corpus situé – et élaboré à la suite d’une lecture comparative des stratégies de neutralisation et de visibilisation du genre avancées par les deux documents institutionnels mentionnés plus haut – en nous inscrivant précisément dans le cadre du multilinguisme européen, où les enjeux liés à l’écriture inclusive sont particulièrement saillants.
Nous précisons d’emblée que, dans le contexte des institutions européennes, les stratégies de neutralisation et de visibilisation du genre renvoient à deux approches rédactionnelles distinctes. Les premières visent à dépasser la prédominance du genre masculin dans les textes – autrement dit, à éviter le recours systématique au masculin générique là où d’autres formulations permettraient de désamorcer l’orientation masculine du discours et de la rédaction (par exemple, en utilisant des expressions neutres ou des formulations épicènes). En revanche, les secondes cherchent à rendre explicite, manifeste, prépondérant ou mis en valeur le genre féminin, que ce soit à travers des choix lexicaux (comme l’emploi de féminins spécifiques), syntaxiques (tels que l’utilisation des accords en double flexion) ou discursifs (comme dans certaines constructions rhétoriques).
Cette double dynamique – entre atténuation de la domination masculine et valorisation de la visibilité féminine – illustre, ainsi, la complexité et la richesse des enjeux liés à l’écriture inclusive, notamment dans un contexte multilingue européen où les traditions linguistiques et les normes socio-culturelles se croisent et se confrontent. Ce cadre situé constitue, donc, le fondement indispensable pour envisager une traduction automatique qui soit véritablement sensible aux questions de genre.
3. Langage inclusif et institutions européennes : lecture comparée des deux recommandations
Cette réflexion nous conduit à examiner, plus en détail, le contexte institutionnel dans lequel s’inscrit la question de l’inclusion. En particulier au sein des institutions européennes, le concept d’inclusion y prend racine dans une trajectoire historique et juridique visant à assurer l’égalité des droits et la participation de tous les individus. Il puise ses origines dans des textes fondateurs tels que le Traité de Rome de 1957, qui affirmait déjà l’importance de promouvoir le progrès social[3], et se manifeste de manière plus explicite dans la Charte des droits fondamentaux de l’Union européenne proclamée en 2000. Cette dernière consacre – notamment à travers ses dispositions sur la non-discrimination, l’égalité entre les sexes et l’intégration des personnes handicapées – l’inclusion comme un principe structurant du droit européen. Ainsi, l’évolution de ce concept au sein des institutions européennes reflète un approfondissement progressif du projet social de l’Union.
Dans une perspective élargie de promotion de l’inclusion sociale et de lutte contre les discriminations systémiques, les institutions européennes ont progressivement intégré la question du langage inclusif comme un enjeu central au sein d’un paradigme normatif soucieux de reconnaître les formes plus subtiles de reconnaissance symbolique et culturelle.
Le langage, en tant que dispositif structurant des représentations sociales, y apparaît comme un vecteur fondamental de reconnaissance, de légitimation et de visibilité des identités. En particulier, dans sa dimension genrée, le langage inclusif se constitue dès lors comme un outil de transformation des rapports sociaux, apte à refléter la pluralité des expériences, à déconstruire les asymétries symboliques et à instaurer une communication institutionnelle qui n’entérine pas les hiérarchies structurelles existantes. C’est dans cette logique que s’inscrit la publication, par la Commission européenne, du Guide pour une communication inclusive en 2018, actualisé en 2023. Ce document s’appuie sur les fondements posés par le gender mainstreaming, principe consacré par le Traité d’Amsterdam (1997) et réaffirmé par la Stratégie pour l’égalité entre les femmes et les hommes 2020-2025.
Au-delà, des simples recommandations stylistiques (emploi de formulations neutres ou épicènes ou abandon des expressions stéréotypées), ce guide engage une réflexion plus profonde sur le pouvoir performatif du langage – au sens bourdieusien du terme (BOURDIEU 2001), dans la mesure où il contribue à (re)configurer les cadres de perception du social tout en engageant des effets concrets sur les pratiques et les dispositifs – et sur sa fonction dans la construction des normes sociales. Dans cette optique, le recours au langage inclusif au sein des institutions européennes peut être interprété comme la mise en œuvre d’un projet politique plus vaste, visant à faire de l’Union un espace de reconnaissance mutuelle, d’égalité effective et de participation équitable de toutes les subjectivités.
Afin de mieux saisir cette ambition, nous avons choisi d’approfondir l’analyse de deux documents : Usage d’un langage neutre du point de vue du genre et Pour l’utilisation d’un langage vecteur d’inclusivité.
Le premier document est un guide élaboré par le Parlement européen et constitue une mise à jour d’un document initialement adopté en 2008. À cette date, le Parlement européen s’est affirmé comme l’une des premières organisations internationales à se doter d’un guide en matière de langage neutre du point de vue du genre, marquant une étape importante dans l’institutionnalisation de l’égalité entre femmes et hommes dans le champ de la communication officielle. La révision de 2018, entreprise à l’occasion du dixième anniversaire du texte, témoigne d’une volonté d’actualisation face à l’évolution des sensibilités sociétales, des usages linguistiques et des enjeux politiques contemporains.
Le document est structuré en deux grandes parties. La première offre une définition de langage inclusif et expose les préoccupations communes à toutes les langues de l’Union : elle aborde notamment les enjeux liés au masculin générique et à la féminisation des titres, fonctions et professions. La seconde partie est consacrée aux stratégies et techniques différenciées pour chaque langue officielle de l’Union européenne. Elle prend en compte les spécificités morphosyntaxiques, lexicales et culturelles propres à chaque idiome, en proposant des exemples concrets pour reformuler les énoncés de manière inclusive, sans nuire à la clarté ou à la fluidité du discours. Dans ce sens, le Guide est rédigé dans toutes les langues officielles de l’Union européenne. Cet ancrage multilingue témoigne de la complexité, mais aussi de la richesse du projet européen d’inclusivité linguistique.
Dans son approche, le guide adopte donc une posture pragmatique : il ne cherche pas à imposer des règles prescriptives universelles, mais encourage une conscience critique et une responsabilité discursive de la part des agents institutionnels. Il propose des solutions souples, adaptables et contextualisés, qui visent à transformer les habitudes langagières tout en respectant les usages professionnels et les normes rédactionnelles de l’administration. En somme, ce document illustre l’engagement du Parlement européen à aligner ses pratiques discursives avec les valeurs fondamentales de l’Union : égalité, dignité, respect de la diversité.
Le deuxième document a été élaboré par le Conseil de l’Europe et il s’agit de Lignes directrices s’inscrivant dans une trajectoire institutionnelle de long terme, marquée par un engagement précoce et constant en faveur de l’égalité entre les femmes et les hommes dans et par le langage. Le Conseil de l’Europe s’est en effet distingué dès 1990 par l’adoption d’une première recommandation aux États membres portant sur l’usage d’un langage non sexiste, suivie, en 1994, de l’Instruction n° 33, qui encadre l’emploi d’un langage non sexiste au sein même de l’Organisation. En 2019, la Recommandation CM/Rec (2019) sur la prévention et la lutte contre le sexisme a réaffirmé l’importance du langage comme espace d’intervention prioritaire, en appelant l’Organisation à « aller plus loin » dans ce domaine.
Les Lignes Directrices de 2024 constituent ainsi une réponse à cet appel, en proposant un cadre actualisé, élargi et structuré pour une communication véritablement inclusive. Comme pour le Guide du Parlement, il ne s’agit pas d’imposer un ensemble de règles contraignantes, ni d’abolir certains mots ou de modifier rétrospectivement des textes historiques. L’objectif est d’encourager les personnes à évoluer vers la mise en œuvre concrète du principe d’égalité, en développant une conscience critique de leurs pratiques langagières et en offrant des alternatives adaptées, souples et respectueuses des contextes.
Ce même document se structure en deux parties complémentaires. La première, à portée générale, expose les fondements théoriques, juridiques et éthiques du langage inclusif. Elle traite également des enjeux transversaux. La seconde partie, à visée plus opérationnelle, présente des stratégies concrètes à mettre en œuvre – respectivement en français et en anglais, selon la version consultée[4] – en tenant compte des spécificités propres à chaque contexte linguistique. Le document comprend aussi deux annexes : l’une consacrée à la féminisation des titres, fonctions, métiers et profession ; l’autre proposant des exemples de textes corrigés selon les principes d’inclusivité énoncés dans la deuxième section.
Particularité importante du document : la dimension pédagogique et évolutive de cette démarche. Car il s’agit moins d’atteindre un idéal figé que d’engager un processus continu d’apprentissage, d’expérimentation et de transformation. L’usage du langage devient ainsi un lieu de responsabilité collective, au service d’une communication plus éthique, plus représentative et plus respectueuse des droits fondamentaux.
4. Vers une traduction inclusive adaptée au contexte européen
C’est dans cette perspective d’adaptation et de respect de la diversité que s’inscrit l’ambition de promouvoir un langage inclusif au sein de l’Union européenne, une ambition étroitement liée à la diversité linguistique (et culturelle) de ses États membres. Garant d’une égalité démocratique, ce multilinguisme intégral peut aussi constituer un terrain de tension. Conscientes de cela, les deux institutions étudiées ont effectivement adopté une approche non prescriptive, mais orientative. Les deux documents mentionnés insistent sur la nécessité de considérer les spécificités morphosyntaxiques, lexicales et culturelles de chaque langue officielle. Plutôt que de promouvoir un modèle uniforme, ces textes encouragent donc – dans chaque version – le développement de stratégies différenciées, car toute tentative d’imposer une formule univoque de langage inclusif serait illusoire. Ainsi, celui-ci est envisagé comme un principe vivant et contextualisé.
Cette posture pragmatique, conjuguée à l’appel en faveur d’une approche interculturelle, invite à une réflexion sur la complexité de la traduction interlinguale. Il ne s’agit pas seulement, selon nous, de transposer des contenus ou reproduire des techniques rédactionnelles inclusives, mais d’assurer une adéquation au contexte cible, en intégrant les préconisations institutionnelles de manière contextualisée. C’est dans ce cadre que s’inscrit la partie appliquée de notre étude, visant à confronter ces recommandations relatives à l’usage d’un langage inclusif à la traduction automatique neuronale. Le but n’est pas seulement d’évaluer si les logiciels TAN sont capables de traiter adéquatement l’écriture inclusive, en termes de fidélité et fluidité (ENGELS 2022) ; mais il s’agit surtout de tester leur capacité à appréhender la dimension situationnelle (EMERY 2021) inhérente au concept d’inclusion – et à l’écriture inclusive telle que définie ici – particulièrement dans le cadre spécifique des institutions européennes.
Il convient de rappeler que l’introduction des recommandations relatives au langage neutre dans une perspective de traduction remonte à 1998, d’abord dans le guide stylistique en anglais de la Direction générale de la traduction (DGT), puis dans les guides interinstitutionnels. Toutefois, l’enjeu demeure : il s’agit, d’une part, de garantir que les traductions respectent les règles et usages propres à chaque institution (Parlement, Commission, Centre de Traduction, etc.), en tenant compte des contextes juridico-politiques et des contraintes linguistiques ; et, d’autre part, d’assurer une harmonisation terminologique interinstitutionnelle, ainsi qu’une communication équitable, représentative et accessible. En connaissance de cause, chaque service linguistique dispose d’une marge d’interprétation. Les traducteurs institutionnels sont invités à concilier l’objectif d’inclusivité avec les normes établies dans leur langue cible, tout en veillant à préserver la lisibilité, la clarté et la fonctionnalité du texte. À ce titre, le Guide précise, par exemple, que « les services de la traduction sont tenus de rendre les textes avec fidélité et précision dans leur propre langue. Si un texte original utilise à dessein un langage marqué du point de vue du genre, la traduction devra respecter cette intention » (Guide : 4).
De même, il reconnaît que :
certaines contraintes, telles que le débit rapide avec lequel les discours sont prononcés, la nécessité de rendre fidèlement ce qui a été dit et les intentions recherchées et de ne pas s’ingérer dans le contenu du message, ainsi que les caractéristiques spécifiques de la parole par rapport à l’écrit, ne permettent pas d’incorporer facilement le langage neutre du point de vue du genre dans l’interprétation simultanée (Guide : 4).
Que se passe-t-il alors avec les logiciels TAN ? Dans quelle mesure ces systèmes sont-ils capables d’intégrer les principes d’un langage inclusif contextualisé dans des environnements (multilingues) institutionnels ?
5. L’analyse outillée
À partir de l’analyse comparative des deux directives sélectionnées (le Guide et les Lignes directrices), nous avons dégagé deux axes structurants relatifs à l’usage inclusif de la langue : d’une part, les stratégies de neutralisation du genre, et d’autres part, les stratégies de visibilisation du genre. Les premières comprennent, entre autres :
- l’évitement des expressions discriminatoires, sexistes ou véhiculant des stéréotypes de genre;
- l’évitement des formulations qui privilégient un genre au détriment de l’autre ;
- l’usage des formulations englobantes, à des noms collectifs ou à des formulations qui permettent une distribution plus égalitaire.
En revanche, les secondes incluent, par exemple :
- l’accord des titres de civilité ainsi que des noms de métier, grade ou fonction lorsque l’identité de la personne est connue ;
Ces distinctions sont essentielles dans une perspective de traduction augmentée (FROELIGER 2023), car elles permettent de mieux adapter les choix linguistiques selon les contextes et objectifs spécifiques liés à l’inclusivité.
-
a. Le corpus
Dans ce cadre, nous avons choisi de concentrer notre analyse sur la paire linguistique italien/français en comparant, dans un premier temps, les versions italienne (La neutralità di genere nel linguaggio usato al Parlamento europeo) et française (Usage d’un langage neutre du point de vue du genre au Parlement européen) du Guide du Parlement européen, puis, dans un second temps, en nous focalisant sur la version française des Lignes directrices. Ce choix repose sur le fait que l’italien et le français sont deux langues à genre grammatical, ce qui limite l’influence de variables parasites susceptibles de générer du bruit méthodologique. L’emploi d’une langue source non genrée, telle que l’anglais, aurait pu entraîner des ambiguïtés structurelles liées à l’absence de marquage morphosyntaxique du genre. Opter pour cette combinaison linguistique visait donc à mieux faire émerger la dimension contextuelle de la traduction inclusive automatique institutionnelle.
Sur la base de cette sélection, nous avons constitué un corpus représentatif composé de 25 phrases emblématiques, élaborées à partir des deux documents institutionnels. Plus précisément, les phrases issues du Guide du Parlement et des Lignes directrices ont été formulées en français en vue d’une traduction vers l’italien. Ce corpus a été conçu de manière à refléter clairement les deux grandes macro-stratégies identifiées précédemment, à savoir la neutralisation et la visibilisation du genre. Par ailleurs, dans certains cas, une retraduction (it > fr) a été également testée afin d’évaluer la sensibilité des systèmes de traduction automatique à gérer les deux sens de la traduction tout en gardant les stratégies de rédaction inclusive initiales. Cette démarche méthodologique a ainsi permis d’explorer non seulement la qualité et la fidélité envers la formulation originale, mais aussi le degré d’inclusivité des corpus utilisés par les TAN dans chacune des deux langues.
Ce corpus a ensuite été soumis à la traduction automatique via trois systèmes neuronaux : DeepL, Google traduction et Yandex (le seul système hybride). Ces traducteurs ont été sélectionnés en raison de leur accessibilité, de leur représentativité parmi les outils de traduction automatique les plus largement utilisés et de leur reconnaissance à grande échelle. Ces caractéristiques les rendent particulièrement pertinents pour une analyse comme la nôtre.
-
b. La méthode d’analyse et la grille d’évaluation
L’analyse repose sur une approche qualitative qui se déploie en trois étapes : l) la création manuelle d’un corpus de phrases à traduire – élaborées à partir des deux documents et des deux principes structurants évoqués précédemment ; 2) la génération des traductions via les traducteurs neuronaux sélectionnés ; 3) l’évaluation des résultats obtenus à partir de quatre dimensions d’analyse : fidélité, fluidité, adéquation linguistique et, surtout, situationnalité. Ces dimensions peuvent être précisées à l’aide des quelques indicateurs synthétisés dans le tableau suivant :
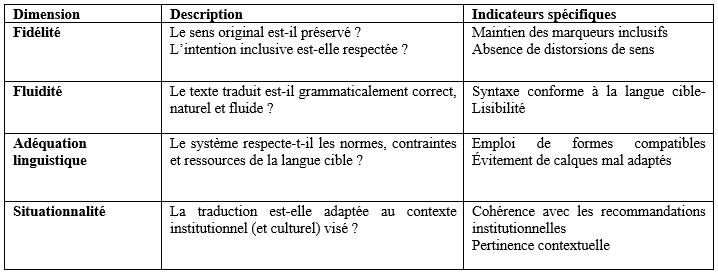
Chaque critère sera noté selon une échelle qualitative (insuffisant, partiellement satisfaisant, satisfaisant, excellent), accompagnée de commentaires justificatifs.
-
c. Cas de figure à partir du Guide du Parlement européen
Nous commencerons par les stratégies de neutralisation du masculin, que nous illustrerons à travers l’ensemble des techniques rédactionnelles recommandées dans les deux versions du Guide (italienne et française). Les phrases à traduire, notamment vers l’italien, ont ainsi été élaborées de manière à mettre en pratique les différentes techniques et vérifier nos hypothèses initiales. Parmi les techniques de neutralisation, on retrouve notamment le recours à des structures grammaticales neutres – telles que l’impératif, la forme impersonnelle ou la voix passive –, l’usage d’expressions génériques ou de termes collectifs, l’emploi du pluriel, ainsi que de formulations non marquées du point de vue du genre. En ce qui concerne les stratégies de visibilité du genre, l’une des plus représentatives est sans doute la féminisation des titres, fonctions et professions.
Le premier cas analysé concerne le recours à l’impératif (ou à des tournures impersonnelles) utilisé pour éviter l’emploi du masculin générique, comme c’est le cas dans la phrase suivante : « *Le candidat enverra son CV à la DGT avant le 31 juillet ». À partir de cet exemple, trois reformulations alternatives ont été élaborées : « Veuillez envoyer votre CV à la DGT avant le 31 juillet » ; « Les CV doivent être envoyés à la DGT avant le 31 juillet » ; « Les CV sont à envoyer à la DGT avant le 31 juillet ». Ces phrases ont ensuite été soumises aux traducteurs automatiques sélectionnés :

Pour ce qui est de la première phrase, les trois systèmes ont correctement évité l’emploi d’un sujet masculin explicite tel que « il candidato ». DeepL traduit fidèlement la phrase d’origine (excellent) et opte pour une construction à l’infinitif, concise et grammaticalement correcte, mais sa fluidité reste moyenne car potentiellement trop elliptique aussi du point de vue de son adéquation linguistique au registre administratif (partiellement satisfaisant). Sur le plan de la situationnalité, c’est-à-dire de l’adéquation au genre de texte et au cadre d’énonciation, la version de DeepL manque de formalisme (partiellement satisfaisant). En revanche, Google propose une tournure impersonnelle formelle « si prega di… », largement utilisée dans la communication institutionnelle italienne. Donc fidélité, fluidité, adéquation linguistique et situationnalité sont excellentes. Yandex adopte une structure similaire, fidèle (excellente) et assez fluide (satisfaisante), mais ajoute l’adjectif possessif « proprio », introduisant un effet de personnalisation qui, bien que grammaticalement correct, peut réactiver implicitement un genre masculin non nécessaire (pour une adéquation linguistique et une situationnalité partiellement satisfaisantes).
Dans le cas de la deuxième phrase, les trois traducteurs produisent une version identique, démontrant une forte convergence autour d’une structure passive neutre, qui respecte à la fois la fidélité (excellente) au contenu source et les exigences d’un langage non genré. La construction est fluide (excellente), formellement adéquate (excellente) et conforme aux standards d’un registre administratif (excellente).
Par rapport à la troisième phrase, DeepL rend ici la formulation plus elliptique, utilisant une tournure synthétique « CV da inviare » qui reste assez correcte (satisfaisant), mais qui peut sembler moins formelle, voire télégraphique (partiellement satisfaisante). De fait, la situationnalité est ici jugée compromise (insuffisante). En revanche, Google et Yandex tendent à homogénéiser les traductions en réutilisant exactement la même structure que pour la phrase précédente « devono essere inviati », ce qui a pour effet d’atténuer la variation stylistique présente dans le texte source. Cela entraîne une satisfaction limitée en termes de situationnalité.
Les trois traducteurs automatiques parviennent, ainsi, à éviter l’emploi du masculin générique en proposant des reformulations neutres ou impersonnelles. Toutefois, des différences stylistiques émergent : DeepL tend à privilégier la concision, parfois au détriment du formalisme ; Google se conforme davantage aux usages institutionnels ; Yandex, enfin, introduit des éléments de personnalisation qui peuvent réactiver subtilement des biais de genre.
Afin de ne pas occulter l’un des sexes, le Guide conseille encore l’emploi d’expressions génériques ou de termes collectifs, y compris pour les titres, les professions et les fonctions. Afin donc d’éviter des formules telles que : « *à tous les employés », « *du président/de la présidente », « *les chercheurs », « *les infirmières », « *les enseignants », « *les électeurs » et « *les sauveteurs », nous avons élaboré trois reformulations telles que : « Tous les scientifiques peuvent bénéficier de cette structure conventionnée avec le Parlement européen », « Le personnel infirmier se tient à la disposition de la population en danger », « Les fiches documentaires sont conçues pour le corps enseignant des établissements scolaires français ». Voici la réponse des traducteurs automatiques :

En ce qui concerne la première phrase DeepL propose une traduction dont la fidélité est excellente car l’ensemble des éléments sémantiques est respecté, sans perte ni distorsion du sens. La fluidité est également excellente : la formulation étant idiomatique, claire et parfaitement naturelle en italien. Par rapport à l’adéquation linguistique, la formulation est satisfaisante, bien alignée sur le registre institutionnel attendu. Toutefois, sur le plan de la situationnalité, le choix du masculin générique « scienziati » pose des problèmes : il n’y a aucune tentative d’inclusivité ni de neutralisation. L’évaluation est donc insuffisante à ce niveau. Google traduction, quant à lui, propose une traduction satisfaisante par rapport à la fidélité, car le syntagme « approvata dal Parlamento europeo » introduit une nuance différente de « a un accord », en orientant l’interprétation vers une validation formelle plutôt qu’un partenariat. La fluidité reste excellente, et l’adéquation linguistique très satisfaisante, avec un lexique approprié et un style maîtrisé. Du point de vue de la situationnalité, l’usage du masculin générique n’est pas corrigé, et la traduction échoue donc à intégrer une perspective inclusive (insuffisante). La version avancée par Yandex est aussi excellente du point de vue de la fidélité et le terme « concordata » rend correctement l’idée d’accord bilatéral. La fluidité est satisfaisante, bien que légèrement plus rigide. L’adéquation linguistique est correcte, sans maladresses notables. Toutefois, comme pour les autres versions, la situationnalité est insuffisante, l’emploi du masculin générique n’étant pas atténué.
Venant à la deuxième phrase, nous remarquons que DeepL propose une version fidèle et fluide, bien construite et lexiquement adéquate (excellente sur ces trois premiers critères). Toutefois, la situationnalité est ici insuffisante car elle véhicule des biais de genre. La traduction de Google rend visible une neutralisation effective du genre par l’emploi d’un terme collectif non marqué. La fidélité est excellente, tout comme la fluidité et l’adéquation. En ce qui concerne la situationnalité, cette version est excellente, car elle évite de reproduire des biais de genre. Dans la version de Yandex la fidélité et la fluidité sont excellentes ; de plus, le remplacement de « les personnes » par « la popolazione » affecte de manière positive aussi l’adéquation linguistique qui apparaît plus institutionnelle. La situationnalité est aussi excellente grâce à la formulation neutre.
Quant à dernière phrase, DeepL fournit une traduction excellente du point de vue de la fidélité, de la fluidité et de l’adéquation linguistique. Toutefois, la situationnalité demeure insuffisante dans la mesure où le terme retenu est marqué ; il aurait été nécessaire, à tout le moins, de recourir à des doublets complets, voire opérer une véritable neutralisation. Google propose une traduction excellente du point de vue de la fidélité et de la fluidité. L’adéquation linguistique est également excellente grâce à une solution élégante et fréquente dans le lexique administratif. Tout comme la situationnalité, car la formulation permet d’éviter le marquage de genre.
Dans l’ensemble, on observe que les trois systèmes de traduction automatiques produisent des résultats globalement fiables du point de vue de la fidélité et de la fluidité, notamment pour les textes de registre administratif. DeepL se distingue par la constance de son idiomaticité, Google Traduction par des solutions de neutralisation efficaces et Yandex par des propositions parfois moins maîtrisées lexicalement. Toutefois, en ce qui concerne la situationnalité, entendue comme la capacité à rendre compte des enjeux discursifs liés à l’inclusivité de genre, DeepL n’intègre jamais de stratégies de neutralisation. Cette limitation souligne, à notre avis, les angles morts persistants dans ce traducteur automatique, et l’importance du jugement humain – notamment dans les contextes comme ceux que nous étudions.
L’usage de tournures non marquées, en plus du recours à des noms épicènes (ou à des adjectifs épicènes, comme dans l’énoncé « La personne apte [*le candidat qualifié] à remplir le poste recevra une convocation »), peut également être exprimé par le choix d’un pronom, comme dans l’emploi de « quiconque » à la place de « celui qui ». Voici donc la phrase soumise à l’évaluation de trois traducteurs automatiques : « Quiconque participe au séminaire peut demander une indemnité ». Et voici les traductions obtenues :

L’analyse comparative des trois traductions met en lumière plusieurs points critiques, tant sur le plan grammatical que terminologique. La version proposée par DeepL présente une altération notable de l’aspect verbal. Par ailleurs, l’utilisation du terme « risarcimento », bien que lexicalement correcte, s’avère inappropriée sur le plan sémantique dans un contexte administratif européen. En revanche, la dimension situationnelle y est bien rendue. Les traductions de Google Traduction et Yandex, identiques dans leurs formulations, se montrent plus conformes sur le plan grammatical. Le pronom « chiunque » y restitue avec justesse la neutralité inclusive de « quiconque », sans marquage genré ni restriction de catégorie. Toutefois, ici encore, le choix du terme « risarcimento » ne correspond pas à la terminologie administrative propre aux documents institutionnels européens. Le terme adéquat serait plutôt « indennità » – plus neutre ou fréquent dans ce registre – et donc, dépourvu de connotations litigieuses.
Lorsque l’on soumet aux trois traducteurs automatiques la phrase en italien « Chi partecipa al seminario può richiedere un’indennità », afin d’en obtenir sa version française originelle, on observe une transformation significative qui touche précisément à la dimension de la situationnalité – à travers laquelle l’on évalue le caractère inclusif ou non de l’énoncé. Celle-ci se trouve donc altérée. Le pronom indéfini « quiconque » est systématiquement omis dans l’ensemble des traductions :

Dans ces trois cas, le pronom (ou le syntagme nominal utilisé) – « les participants » et « ceux qui » – tend à restreindre la portée de l’énoncé à une catégorie identifiable, ce qui va à l’encontre de l’abstraction inclusive initialement présente dans le « chi » italien, lequel fonctionne comme un opérateur d’universalité impersonnelle et neutre. Ce glissement n’est pas anodin. Il révèle, selon nous, une carence structurelle dans les corpus d’entraînement relatifs à la langue italienne[5].
Dans le cadre de cette réflexion, un point particulièrement révélateur concerne l’usage des noms de profession ou de fonction. Le Guide précise que « [l]orsque le texte se réfère à une catégorie générale de personnes, qui peuvent être aussi bien des femmes que des hommes, la forme masculine du nom de profession est généralement employée » (Guide : p. 14). Cependant une exception est reconnue dans le cas où l’on « souhaite viser non pas toutes les personnes ayant exercé cette profession ou fonction, mais uniquement les femmes » (Guide, p. 14). Or, ce caractère d’exceptionnalité n’est pas reconnu, comme le montrent les traductions de l’énoncé que nous avons soumis aux trois traducteurs neuronaux, à savoir : « Simone Veil a été le premier président du Parlement européen directement élu » :

Les résultats en italien sont très proches, voire identiques. Et c’est notamment sur le plan de la situationnalité que les traductions résultent insuffisantes. En effet, les trois traducteurs visibilisent le genre féminin plutôt que de cibler la fonction générale en gardant le masculin générique. Une légère différence est à peine perceptible dans la version de Google, du moment que la phrase à traduire véhicule plus clairement l’exigence d’une valorisation explicite du genre féminin au détriment de la catégorie. Voici donc les traductions de ce deuxième énoncé : « Simone Veil a été la première présidente du Parlement européen » :

Dans un cas comme dans l’autre, les trois traducteurs ne perçoivent pas la contrainte situationnelle. Ces exemples montrent, alors, que les systèmes de traduction automatique neuronale sont encore peu sensibles aux contextes discursifs exceptionnels et cet énoncé pose un défi dans la mesure où il conjugue le genre grammatical du titre et le genre référentiel explicite de la personne nommée – ce qui exerce une pression vers une féminisation de la fonction. La contrainte grammaticale imposée par le genre référentiel du sujet conduit ici à des effets de féminisation et de visibilisation du genre non requis et contraires aux préconisations du Guide. Dans certains cas, donc, une moindre inclusivité linguistique ne constitue pas un manquement aux principes d’un langage inclusif, mais au contraire une exigence contextuelle, voire une obligation discursive.
C’est précisément ce qui se joue dans cet autre cas. En effet cette tension entre inclusivité formelle et exigence contextuelle est aussi observable grâce à l’usage générique du terme « homme ». Le Guide ainsi que les Lignes directrices précisent qu’il est « recommandé d’éviter l’usage générique du terme homme et de lui préférer des expressions qui englobent tous les sexes » (Guide : 13). Sont ainsi conseillées des reformulations telles que : « les responsables (les *hommes politiques) politiques », « les juristes (les *hommes de loi) », « les milieux d’affaires (les *hommes d’affaires) » et « la jour-personne (le *jour-homme). Il est aussi convenu de reformuler les expressions composées à partir du terme « homme », comme c’est le cas pour : « droits humains » (au lieu de *droits de l’homme) ou « l’humanité/les êtres humains » (au lieu de *l’homme, *les hommes).
Ces recommandations témoignent d’une prise de conscience progressive des biais linguistiques ancrés dans la terminologie professionnelle et institutionnelle. Cette dernière suppose donc une relecture critique des usages hérités, et appelle à une reconfiguration des référents collectifs dans la langue. Toutefois, il convient de nuancer cette exigence d’évitement du masculin générique, car certaines expressions, bien qu’ostensiblement non inclusives sur le plan formel, demeurent irréductibles dans leur formulation en raison de leur ancrage juridique, politique et historique.
C’est notamment le cas de l’expression « droits de l’homme », que l’on pourrait, en théorie, reformuler sous des formes plus inclusives comme droits humains ou droits de la personne. Or, le Guide et Les Lignes directrices précisent qu’il n’est pas recommandé de s’écarter de l’expression « droits de l’homme », dans la mesure où celle-ci désigne un concept politique et philosophique consolidé, et qu’elle est largement consacrée par l’usage dans les textes juridiques internationaux. Il s’agit notamment de documents fondamentaux tels que la Déclaration universelle des droits de l’homme ou encore la Convention européenne des droits de l’homme, où cette terminologie est non seulement stabilisée, mais également porteuse d’une mémoire historique, d’une force normative et d’une valeur symbolique partagée. Dans ce cas précis, l’option la moins inclusive sur le plan lexical devient donc la plus adéquate sur le plan institutionnel et juridique. Elle répond à une logique de pragmatisme terminologique, propre aux milieux institutionnels, qui privilégient la continuité, la cohérence intertextuelle et la reconnaissance des cadres de référence.
Afin d’évaluer la manière dont les TAN traitent cette expression, nous avons conçu trois énoncés à traduire vers le français : « Tous les textes de l’Organisation font référence à la Cour européenne des droits de l’homme », « Tous les textes de l’Organisation font référence à la Déclaration universelle des droits de l’homme » et « Tous les textes de l’Organisation font référence à la Convention européenne des droits de l’homme ». Voici ce qui en est ressorti :

Sur le plan de la fidélité, l’ensemble des traducteurs maintient une très bonne correspondance (excellente) avec les énoncés originaux. Aussi du point de vue de la fluidité (excellente), toutes les traductions présentent des phrases grammaticalement correctes, naturelles en italien et sans ruptures syntaxiques ou lexicales. La lisibilité est bonne, aucun choix ne nuit à l’intelligibilité de l’énoncé.
En matière d’adéquation linguistique, c’est-à-dire de respect des normes de la langue cible, les résultats sont excellents, à une exception près : Yandex applique une capitalisation abusive (Corte Europea, Diritti dell’Uomo), contraire aux conventions typographiques de l’italien administratif, où seules les majuscules initiales des entités officielles doivent être respectées avec cohérence (Corte europea dei diritti dell’uomo, par exemple).
Mais c’est sans doute sur le plan de la situationnalité que les divergences sont les plus significatives. En effet, le cadre institutionnel et juridique impose ici le respect de terminologies consacrées (LAFORCADE et al. 2025). Or, un problème se manifeste dans la deuxième phrase avec DeepL et Google Traduction, qui traduisent l’énoncé « Déclaration universelle des droits de l’homme » en substituant « dell’uomo » par « umani », c’est-à-dire en réalisant une généralisation inclusive mais non fidèle.
Cette reformulation introduit une distorsion conceptuelle, qui bien que motivée – peut-être – par un souci d’inclusivité, n’est pas justifiée dans le contexte juridique, où l’expression originelle conserve un sens propre et historiquement ancré. Il s’agit donc d’un cas paradigmatique où une moindre inclusivité est non seulement justifiée, mais requise. Dans ce contexte, Yandex, malgré ses maladresses typographiques, apparaît comme le seul traducteur qui maintient l’équilibre attendu entre précision, fidélité et pertinence situationnelle.
En passant, il est également intéressant de noter le comportement contrasté des TAN lorsque l’on tente de revenir au français à partir de la traduction italienne fautive – en l’occurrence, celle où « droits de l’homme » avait été rendu par « diritti umani ». Ce test inverse met en évidence une différence de traitement révélatrice. Google Traduction reproduit une formulation dite inclusive, en restituant en français : « Déclaration universelle des droits humains ». Ce choix reflète, à notre avis, une logique d’usage généralisé en français (peut-être sous l’influence de l’anglais « human rights »), mais il fait fi des exigences de cohérence terminologique propres au discours institutionnel.
À l’inverse, DeepL corrige la forme italienne fautive et revient spontanément à la formulation historiquement et juridiquement établie. Ce comportement pourrait témoigner d’une plus grande sensibilité des corpus d’entraînement français au cadre d’usage spécialisé du texte source, ainsi qu’à la portée référentielle de l’expression.
Or, afin de mieux visualiser les résultats et de conférer une plus grande lisibilité aux développements discursifs et argumentatifs développés ci-dessus, nous proposons en conclusion de ce paragraphe la présentation d’un tableau synthétique. Ce tableau ressemble les quatre dimensions essentielles à notre analyse (fidélité, fluidité, adéquation et situationnalité), évaluées sur une échelle de 1 (insuffisant) à 4 (excellent). Il s’agit ici des valeurs moyennes, obtenues en faisant la somme de toutes les notes individuelles attribuées à chaque phrase traduite, en tenant compte de l’ensemble des procédés inclusifs examinés :
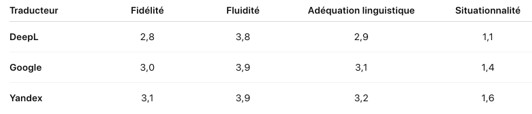
Le tableau met en lumière une qualité élevée sur les trois premiers critères, attestant de la bonne maîtrise linguistique et stylistique des traducteurs automatiques. En revanche, la situationnalité – dimension cruciale pour rendre visibles les stratégies inclusives, et notamment celles de neutralisation du genre – reste nettement plus faible, traduisant une difficulté systématique à intégrer des éléments inclusifs dans la traduction automatique neuronale.
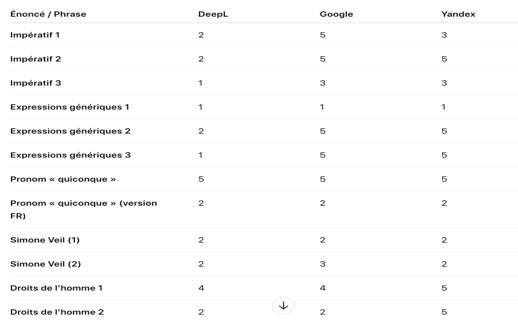
Pour approfondir cette dernière dimension, nous présentons également deux graphiques spécifiques, l’un basé sur des notations – échelle de 1 (situationnalité absente ou effacée) à 5 (situationnalité pleinement respectée) –, et l’autre sur des pourcentages. Les deux permettent d’illustrer le positionnement moyen des trois traducteurs sur l’axe de la situationnalité. Ces évaluations se basent sur le traitement des stratégies rédactionnelles inclusives telles que recommandées par le Parlement européen dans le Guide, et sont élaborées à partir des phrases précédemment analysées.
La synthèse de ces résultats, convertis en pourcentages moyens de réussite sur l’échelle maximale de 5, offre un aperçu encore plus éclairant de l’(in)efficacité situationnelle de chaque système :
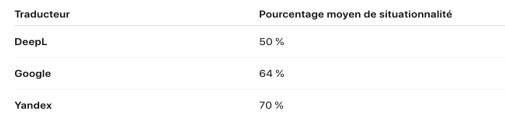
Ces données, en somme, bien que révélatrices de progrès relatifs, témoignent également d’une certaine réserve algorithmique face aux transformations normatives encore émergentes dans la langue cible et que l’on peut définir en termes de « disallineamento linguistico […] che riflette, pertanto, la difficoltà del modello nel gestire il cambiamento linguistico [e nel] rappresentare adeguatamente le trasformazioni sociali e culturali in atto, con particolare riguardo all’inclusività » (RUSSO 2025 : 221).
Plus précisément, le traducteur DeepL – malgré une excellente fluidité linguistique – se montre le moins sensible à la situation discursive, avec une propension marquée à gommer les marqueurs d’inclusivité. Google, avec un score légèrement supérieur, présente une flexibilité plus nuancée, notamment dans les cas d’impératif inclusif ; tandis que Yandex, souvent considéré comme plus conservateur, surprend ici par sa performance, atteignant 70 % de conformité situationnelle – résultat qui semble indiquer une meilleure adaptation contextuelle aux normes discursives véhiculées par les textes sources.
Enfin, cette hiérarchisation invite à repenser les critères d’évaluation usuels des systèmes de traduction : au-delà de la seule correction grammaticale ou de la fidélité lexicale, c’est bien dans la capacité à intégrer les dimensions idéologiques, sociales et institutionnelles du discours que réside l’enjeu majeur de la traduction dans les contextes multilingues européens.
- d. Cas de figure à partir des Lignes directrices du Conseil de l’Europe
Poursuivons maintenant notre analyse à partir de cas concrets inspirés des Lignes directrices du Conseil de l’Europe, en approfondissant les stratégies de visibilité du genre. Deux procédés emblématiques sont ici mis en lumière : d’une part, le recours à la double désignation (par exemple, « les députés et les députées ») et, d’autre part, l’accord de proximité, qui déroge à l’accord grammatical traditionnel pour privilégier la logique d’égalité représentationnelle.
S’agissant de l’usage des doublets – qu’ils soient complets ou abrégés – nous avons choisi de soumettre aux trois traducteurs automatiques un ensemble d’énoncés-types issus directement du document de référence, que nous avons adapté avec précaution. Ces phrases – en français – incluent intentionnellement des doublets, aussi bien au niveau des substantifs (« Les candidates et les candidats à la présidence pourront présenter leur candidature jusqu’au 1er juin »), des titres ou fonctions (« L’experte ou l’expert est dans l’obligation de fournir une facture avant la fin de l’année » ; « Les agentes et les agents ont droit à un congé parental même en cas d’adoption ») ou encore des pronoms personnels (« Celles et ceux qui souhaitent travailler à temps partiel pourront le faire suite à l’acceptation de leur demande »). Ces formulations nous ont paru particulièrement pertinentes dans le cadre des ressources humaines, un champ privilégié des institutions que nous avons pris pour objet d’étude. Voici les énoncés traduits en italien :

Le premier énoncé mobilise un doublet complet que les trois traducteurs ignorent, effaçant ainsi la visibilité du genre explicitement recherchée. Si le sens global est préservé, cet effacement altère toutefois la dimension inclusive de la formulation (fidélité partiellement suffisante). Sur le plan morphosyntaxique, les trois traductions sont correctes et naturelles (fluidité satisfaisante), mais le recours systématique au masculin générique va à l’encontre de l’intention communicationnelle du texte source, et affaiblit la portée sociolinguistique de la mesure d’écriture inclusive promue par l’institution concernée (adéquation linguistiques et situationnalité insuffisantes).
Le deuxième énoncé est quant à lui restitué dans les trois cas sous une forme exclusivement au masculin, effaçant une nouvelle fois la stratégie de visibilité du genre. Cette suppression altère l’intention inclusive, entraîne un appauvrissement stylistique et diminue la portée du discours de l’institution. Par conséquent, les dimensions de l’évaluation – en particulier la fidélité, l’adéquation stylistique et la situationnalité – se trouvent ici compromises.
Le troisième énoncé repose sur un doublet pronominal. Là encore, aucune des traductions ne conserve cette structure. En revanche, toutes optent pour une tournure générique impersonnelle en l’occurrence « coloro », qui neutralise le genre plutôt que de le visibiliser. Si le contenu informatif est respecté et que la syntaxe est fluide et idiomatique, le choix grammatical opéré privilégie une stratégie de neutralisation, certes recevable, mais qui va à l’encontre de la logique inclusive de départ. Il s’agit donc d’un compromis linguistique, acceptable sur le plan pragmatique, mais discutable en termes d’intentionnalité.
Enfin, le quatrième énoncé présente deux types de solutions traductives. Google et Yandex choisissent une généricité masculine (« agenti »), tandis que DeepL propose un hyperonyme plus neutre (« dipendenti »). Si cette dernière solution peut sembler plus inclusive d’un point de vue lexical, elle nécessiterait également d’une double désignation pour refléter fidèlement l’intention du texte source. Ainsi, bien que les traductions soient claires et idiomatiques, et que le sens global soit respecté (fidélité partiellement satisfaisante), la stratégie de visibilisation est systématiquement ignorée, ce qui impacte défavorablement les trois autres dimensions. En synthèse, l’analyse de ces quatre cas révèle une tendance constante de ces traducteurs neuronaux à effacer les doublets, en leur préférant soit des formulations au masculin générique, soit des structures neutres (pronominales ou lexicales).
Le dernier procédé stylistique de visibilisation du genre que nous souhaitons soumettre à l’épreuve des trois systèmes de traduction neuronale concerne l’usage de l’accord de proximité. Ce procédé, historiquement très présent dans la langue française, comme le rappelle aussi Viennot (2017), a progressivement été marginalisé à la suite du processus de normalisation linguistique imposé par les diverses rhétoriques institutionnelles postérieures à la création de l’Académie française. Il constitue pourtant une ressource interne à la langue, mobilisable sans bouleversement majeur de la syntaxe ou de la grammaire, permettant de rendre visible le genre féminin. L’accord de proximité consiste, par exemple, à faire l’accord du participe passé d’un verbe avec le nom le plus proche, indépendamment du genre grammatical dominant selon la règle classique. Ainsi, dans un groupe coordonné composé d’un substantif masculin et d’un substantif féminin, si le nom féminin est placé au contact du participe, c’est ce dernier qui détermine l’accord.
Les Lignes directrices du Conseil de l’Europe encouragent cette pratique : « nous vous proposons de recourir à l’accord de proximité, lorsque cela est possible » [comme dans le cas des] adjectifs épithètes et [d]es pronoms […], des adjectifs attributs » (Lignes directrices : 17). Sur la base de ces recommandations, nous avons élaboré quatre énoncés destinés à tester la manière dont les TAN traitent ce type d’accord dans un cadre institutionnel : « Le Président du Parlement européen a invité les étudiants et les étudiantes lauréates », « Le Président du Parlement européen a invité les étudiants et les étudiantes lauréates des bourses d’excellence à participer à la cérémonie » ; « Les étudiants et les étudiantes lauréates ont été reçues par le Président du Parlement européen », « Les hommes et les femmes sont égales en droits ». Voici les traductions obtenues :

L’analyse des traductions révèle, à l’instar des exemples mobilisant les doublets, une tendance à la neutralisation des mécanismes de visibilité du genre. L’ensemble des traductions en italien témoigne d’un choix généralisé pour la simplification morphosyntaxique, ignorant la possibilité d’exploiter pleinement les ressources expressives de la langue cible.
Dans le premier énoncé examiné, les trois traducteurs automatiques proposent la même formulation, éliminant les doublets et recourant exclusivement au substantif masculin pour désigner de manière générique les deux genres (« étudiants et étudiantes »). Il en va de même pour le deuxième énoncé, qui comportait une expansion explicative (« les bourses d’excellence ») susceptible de préciser le contexte. Ici encore, les systèmes optent pour une tournure masculine générique ou impersonnelle, sans tenter de restituer la structure inclusive présente dans l’original. Ainsi, les traductions en italien offrent un portrait limité de ses potentialités expressive au niveau morphosyntaxique. On observe par ailleurs, l’absence notable de recours aux formes lexicales ou pronominales inclusives disponibles en italien (telles que « studenti e studentesse, coloro che… »), ce qui suggère une instabilité manifeste dans les stratégies traductives mobilisée par les trois traducteurs testés.
Le troisième énoncé analysé confirme cette tendance : bien que le contenu informationnel soit globalement restitué, l’intention inclusive du texte source est marginalisée, voire entièrement effacée. La traduction se réduit ainsi à un transfert référentiel, au détriment de la performativité sociale du discours d’origine.
À titre d’exemple, et afin de démontrer que l’italien permet lui aussi, dans certains cas, de recourir à l’accord de proximité en contexte inclusif, nous proposons ici une série de traductions humaines des trois premiers énoncés analysés. Ces reformulations visent à restituer fidèlement l’intention inclusive du texte source, tout en respectant les structures grammaticales de la langue cible :

Ces traductions pourraient, à notre avis, être considérés comme des paramètres de référence illustrant la possibilité, dans un italien soigné et idiomatique, d’adopter un accord au féminin lorsqu’il est déclenché par la proximité du nom féminin dans une coordination mixte. Cette stratégie, bien que non encore codifiée dans la norme grammaticale italienne, s’inscrit dans une dynamique linguistique inclusive de plus en plus reconnue dans les usages administratifs, journalistiques et académiques.
Comme l’affirme Giusti, en s’appuyant sur les recherches de Merkel (2017) : « [q]uesto costituisce una violazione alla norma del maschile non marcato, ed è quindi meno accettabile […] [allo stesso tempo] questo tipo di uso potrebbe contribuire a creare il femminile non marcato con interpretazione inclusiva di entrambi i generi » (GIUSTI 2022 : 11).
En ce qui nous concerne à présent, nous avançons que plus qu’une transgression de la norme, les traductions humaines représentent une relecture fonctionnelle et socialement consciente de ses marges de manœuvre. En ce sens, ces traductions visent à illustrer la capacité du traducteur humain à combiner lisibilité, fidélité discursive et sensibilité politique du langage. Ce contraste met en évidence, en définitive, le potentiel transformateur de la traduction humaine lorsqu’elle est guidée, comme nous le croyons, par une éthique de la visibilité et de la représentativité dans le langage.
En reprenant maintenant le dernier exemple – Les hommes et les femmes sont égales en droits – qui applique l’accord de proximité à un adjectif attribut, nous observons que cet énoncé est particulièrement révélateur des asymétries structurelles entre le français et l’italien. Les traductions en italien (« Uomini e donne hanno pari diritti » et « Uomini e donne sono uguali nei diritti ») sont linguistiquement correctes et idiomatiques, mais ne permettent pas, en raison de la structure morphologique de l’italien, de conserver la logique de l’accord avec « donne ». Ici, le passage d’une langue à l’autre révèle un véritable écart : l’accord de proximité, aisément mobilisable en français, ne trouve ici pas d’équivalent fonctionnel en italien.
Or, dans le but d’examiner si une substitution de « égales » par un équivalent potentiellement plus recevable dans le contexte morphosyntaxique de la langue italienne pouvait produire un ajustement pertinent, nous avons reformulé l’énoncé de la manière suivante : « Hommes et femmes sont identiques en droits ». Il s’agit ici d’un énoncé exploratoire conçu ad hoc pour déterminer si l’accord de proximité en italien figure parmi les solutions que les TAN sont capables de générer. Nous aspirons ainsi à tester la réaction de ces dernières face à un adjectif dont la valeur en français est épicène, mais dont la traduction italienne (« identici » vs « identiche ») implique une obligation d’accord genré. Ce décalage entre les deux systèmes linguistiques devrait, théoriquement, encourager un accord de proximité dans la langue cible, c’est-à-dire un ajustement syntaxique fondé sur la position la plus proche du nom féminin (« femmes »), plutôt que sur une hiérarchie grammaticale rigide. Voici donc ce que nous avons obtenu :

Parmi ces traductions, seule celle de Yandex conserve une correspondance lexicale fidèle à l’énoncé source. Cette option, bien qu’imparfaite, témoigne d’un effort de préservation de la sémantique de l’original, là où les deux autres traducteurs (DeepL et Google) proposent des reformulations plus libres et identiques à celles avancées précédemment. Cependant, même dans le cas de Yandex, l’accord de proximité, qui constitue le point névralgique de cet énoncé expérimental, n’est pas maintenu. En somme, la réponse négative à notre remplacement intentionnel – non pas en direction de la langue source mais de la langue cible, pourrait signaler un déficit structurel dans les corpus d’entraînement italiens, notamment en ce qui concerne les usages émergents ou non normatifs, tels que ceux mobilisés par l’écriture inclusive.
À l’instar des stratégies de neutralisation, nous concluons ce paragraphe per un tableau synthétique des évaluation attribuées à chacun des TAN, selon une échelle graduée de 1 à 4, pour chaque critère et pour chacune des stratégies utilisées.
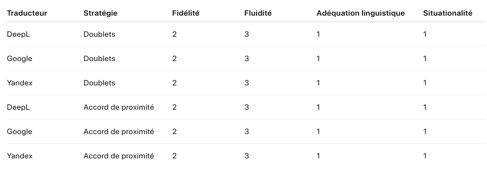
Ces résultats illustrent bien les contraintes inhérentes aux systèmes neuronaux, qui tendent à privilégier la simplification morphosyntaxique au détriment des nuances discursives et sociolinguistiques essentielles à la traduction inclusive, notamment de type institutionnel[6]. Ils soulignent ainsi l’impératif d’une (re)médiation humaine pour assurer une traduction consciente du contexte. Il convient également de souligner que les stratégies de visibilisation obitiennent des scores inférieurs à ceux des procédés de neutralisation du genre, dans le cadre institutionnel européen. En conséquence, la dimension performative e sociolinguistique du texte source, qui vise une représentation effective et égalitaire des genres, est significativement affaiblie. En somme, ces outils de traduction neuronale actuels paraissent moins aptes à intégrer les formes linguistiques émergentes et non encore normées, contrairement à une plus grande tolérance pour les solutions neutres.
Conclusion
À l’heure où le concept d’inclusion s’impose comme un référent central dans les discours contemporains, sa portée réelle ne saurait être appréhendée indépendamment des contextes dans lesquels il est mobilisé, des ressources linguistiques qu’il convoque, et des pratiques concrètes qu’il engage. Ce que nous avons désigné au fil de ces pages comme la dimension situationnelle de l’inclusion est particulièrement perceptible à travers le cas de l’écriture inclusive – devenue objet d’intenses débats tant au niveau national que supranational – et de sa traduction interlinguale.
Dans cette étude, nous avons insisté sur le fait que l’inclusion n’est pas un principe abstrait, mais se matérialise dans des formes linguistiques situées, soumises à des enjeux politiques, culturels et discursifs différenciés. C’est dans cette perspective que nous avons entrepris d’analyser la manière dont les institutions européennes formulent leurs recommandations en matière d’écriture inclusive – domaine dans lequel se croisent les problématiques de genre, de diversité linguistique et de traduction institutionnelle – afin de proposer des principes de communications communs, tout en respectant la variété des langues officielles, des sensibilités nationales et des normes grammaticales divergentes.
À partir donc de l’analyse de deux documents majeurs relatifs à la communication inclusive en milieu institutionnel, nous avons étendu notre réflexion aux TAN, comme outil d’implémentation (ou non) de ces recommandations. Un corpus de phrases à traduire, conçu ad hoc pour exemplifier ces principes, a constitué notre terrain d’observation. Nous avons alors cherché à déterminer si ces systèmes (notamment, DeepL, Google Traduction, Yandex) – désormais omniprésents dans les pratiques de traduction, tant institutionnelles (FOTI 2022) que quotidiennes – sont en mesure d’intégrer dans leurs traductions les principes d’inclusivité définis par les institutions européennes en question. L’analyse des traductions obtenues a montré une tendance des TAN testés à reproduire des formes génériques dominantes, à manifester leur insensibilité à certaines stratégies de prise en compte du genre et à révéler leurs défaillances face à la dimension situationnelle[7] des phrases à traduire. Nos trois hypothèses initiales se retrouvent ainsi confirmées.
Notre analyse a révélé, surtout, une tendance récurrente de ces systèmes à recourir par défaut à des formes masculines génériques (ou neutres), occultant les procédés inclusifs de visibilité pourtant explicitement présents dans nos phrases sources. Si les traductions obtenues remplissent, dans une certaine mesure, les critères de fluidité syntaxique et de fidélité référentielle – dans la lignée de Engels (2022) –, elles échouent de manière ponctuelle à rendre visible l’intention inclusive des phrases sources. Cette neutralisation systématique concerne tout particulièrement l’effacement des doublets et le refus de l’accord de proximité. La variabilité inter-système, observée même face à des énoncés simples construits selon des stratégies inclusives assez communes, souligne par ailleurs l’instabilité des solutions proposées. Ce déficit de cohérence traduit non seulement les limites structurelles des corpus d’entraînement (spécialement pour la langue italienne), mais aussi un manque de conscience stylistique dans les algorithmes qui pilotent ces outils. Nous confirmons donc que les technologies neuronales sont des aides précieuses pour le traitement linguistique, mais elles sont à présent inadaptées à la traduction des dimensions situationnelles.
À la lumière de nos résultats, plusieurs pistes d’amélioration se dessinent. Il s’agirait notamment d’intégrer, au sein des corpus d’entraînement, des guides de style inclusifs multilingues, rigoureusement annotés afin de refléter les variations linguistiques et les normes émergentes en matière d’inclusivité. Dans le même esprit, certains chercheurs soulignent la nécessité de renforcer l’apprentissage à partir de corpus explicitement inclusifs (PIERGENTILI et al. 2023), comprenant une diversité d’exemples rédactionnels et typographiques – tels que les doublets – ainsi que des formes linguistiques innovantes, capables de mieux représenter la pluralité des identités et des usages. Dans le prolongement de ces réflexions, Cennamo propose les fondements d’« une définition de traduction inclusive comme compétence langagière d’aide pour la pré-édition de corpus d’entraînement destinés à la création de moteurs intelligents » (2025 : 211). Parallèlement, un autre axe d’intervention concerne les techniques de mitigation appliquées aux données d’entraînement, visant à réduire les biais systémiques et à améliorer la représentativité des contenus linguistiques inclus. À ce propos Russo affirme :
Tra queste, il pre-processing data può giocare un ruolo chiave: individuare e correggere le distorsioni prima della fase di training del modello, potrebbe permettere di ridurre significativamente l’influenza dei bias a monte. Tecniche come l’utilizzo di dati sintetici, la raccolta di dati aggiuntivi riferiti a gruppi sottorappresentati insieme ad un’attenta filtrazione dei contenuti che presentano bias espliciti e impliciti, se applicati in maniere sinergica, possono garantire dataset più diversificati, inclusivi e rappresentativi. Tuttavia, è essenziale che tali azioni siano integrate in un quadro più ampio che preveda un monitoraggio continuo, la valutazione critica degli output e una costante riflessione etica sulla progettazione e implementazione tecnologica (RUSSO 2025 : 223).
En outre, le développement d’outils de post-édition assistée, sensibles aux enjeux de genre et de représentation, apparaît également comme une voie prometteuse. Enfin, il est impératif de promouvoir une formation critique des traducteurs et traductrices (CENNAMO 2018 ; CENNAMO, DE FARIA PIRES 2022 ; CENNAMO, HAMON 2023 ; CENNAMO, MATTIODA 2025 ; D’ANGELO 2012 ; MATTIODA et al. 2023), à la fois sur le plan technique, linguistique et idéologique. Cette approche holistique devrait favoriser l’émergence de traductions plus inclusives et situées et un usage plus conscient et responsable des technologies de traductions neuronales.
En général, nos constats appellent une réflexion approfondie sur le rôle des traducteurs humains dans l’implémentation des normes inclusives. L’usage des TAN, aussi performant soit-il en termes de traitement lexical, ne saurait dispenser d’un travail critique et éthique d’analyse, de révision et de correction, en particulier lorsque les textes en question véhiculent – comme dans notre cas – des valeurs sociales et politiques fortes. Les défaillances observées face à la traduction de phrases contenant, par exemple, des doublets ou des accords de proximité signalent avec force la nécessité d’un réinvestissement humain du travail traductif, l’intervention humaine demeurant essentielle afin de pallier les erreurs systémiques et de corriger les biais inhérents aux processus automatisés (AA.VV. 2025). De plus, elle est indispensable pour identifier les « invenzioni algoritmiche » (DE CESARE 2025 : 80), à savoir des morphèmes artificiels créés par les modèles, inexistants dans la langue naturelle, que l’on pourrait comparer à de fausses créations grammaticales.
En ce sens, la traduction automatique s’est révélée à nous comme un véritable terrain d’analyse critique, non seulement pour évaluer l’état de l’art technologique (YVON 2022), mais aussi pour interroger l’inclusion comme processus dynamique, conflictuel et situé (BUTLER 1999). Dès nos jours, l’acte de traduction devrait représenter un moment stratégique d’intervention militante, en particulier à travers les pratiques de post-édition qui permettent aux traducteurs et traductrices de corriger, contester et réorienter les productions automatisées vers une réelle inclusivité. Ainsi pensée, la traduction automatique inclusive que nous nous sommes efforcés de rechercher ne peut qu’être un acte performatif où se négocient les conditions d’une parole juste et partagée (CRONIN 2013 ; MESCHONNIC 1999).
Bibliographie
AA.VV., Inclusione ed elaborazione del linguaggio naturale nell’era dell’intelligenza artificiale generativa, Milano, Ledizioni 2025.
AMADORI, Sara, et al., La traduction dans une perspective de genre. Enjeux, politiques, éditoriaux, Milano, LED 2022.
AMOSSY, Ruth, HERSCHBERG PIERROT, Anne, Stéréotypes et clichés : langue, discours, société. Paris, Nathan / Armand Colin, 1997.
BAEZA-YATES, Ricardo, « Bias on the web », Communications of the ACM, n. 61, vol. 6, 2018, p. 54-61.
BERGER, Anne Emmanuelle, « Le genre de la traduction : introduction », Revue De Genere, n. 5, 2019, p. I-XII.
BOURDIEU, Pierre, Langage et pouvoir symbolique, Paris, Seuils, 2001.
BUTLER, Judith, Gender trouble. Feminism and the subversion of Identity, London, Routledge, 1999.
CADWELL, Patrick, et al., « Human factors in machine translation and post-editing among institutional translators », Translation Spaces, n. 5, vol. 2, 2016, p. 222–243.
CENNAMO, Ilaria, Enseigner la traduction humaine en s’inspirant de la traduction automatique. Rome, Aracne, 2018.
CENNAMO, Ilaria, « Le langage inclusif : un savoir-faire traductologique. Pour une réflexion sur l’inclusion à l’aune de l’intellegence artificielle », In AA.VV., Inclusione ed elaborazione del linguaggio naturale nell’era dell’intelligenza artificiale generativa, Milano, Ledizioni 2025, p. 211-216.
CENNAMO, Ilaria, FARIA PIRES, Loïc, « Intelligence artificielle et traduction : les défis pour la formation et la profession », In MAGGI, L., BORDES, S., Intelligences pour la traduction. IA et interculturel : actions et interaction, John Benjamins Publishing Compagny, 2022, p. 333-353.
CENNAMO, Ilaria, HAMON, Yannick, « L’offre de formation en traduction : objectifs et compétences dans les contextes universitaires français et italiens », In T. LEVICK, S. PICKFORD, Enseigner la traduction dans les contextes francophones, Arras, Artois Presses Université, 2023, p. 221-238.
CENNAMO, Ilaria, MATTIODA Maria Margherita, « L’intelligence artificielle au service du multilinguisme : quels enjeux pour le français et l’italien ?, MediAzioni, n. 46, vo. 1, 2025, p. 65-81, en ligne.
COSTA-JUSSÀ, Marta Ruiz, « An analysis of gender bias studies in natural language processing », Nature Machine Intelligence, n. 1, vol. 11, 2019, p. 495-496.
CRIADO-PEREZ, Caroline, Invisible Women : Exposing Data Bias in a World Designed for Men, LondreS, Chatto & Windus, 2019.
CRONIN, Michael, Translation in the Digital Age, First, London, 2013.
D’ANGELO, Maria Pia, Traduzione didattica e didattica della traduzione. Percorsi teorici, modelli operativi, Urbino, Editore Quattroventi, L’officina del Linguaggio, 2012.
DE CESARE, Anna-Maria, « L’intelligenza artificiale generativa al servizio della parità di genere : uno studio esplorativo sugli annunci di lavoro della Confederazione svizzera », In AA.VV., Inclusione ed elaborazione del linguaggio naturale nell’era dell’intelligenza artificiale generativa, Milano, Ledizioni 2025, p. 59-83.
EMERY, Leonor Emili (2021). Traduction non sexiste : quo vadis ? État des lieux de l’écriture inclusive et exercice pratique pour la combinaison italien-français, Thèse de doctorat en ligne.
ENGELS, Lise, Écriture inclusive : incidence sur la traduction automatique fondée sur le corpus, Mémoire de Master, 2022.
FOTI, Markus, « eTranslation. Le système de traduction automatique de la Commission européenne en appui d’une Europe numérique », Traduire, n. 246, 2022, p. 28-35.
FROELIGER, Nicolas, et al., Traduction humaine et traitement automatique des langues. Vers un nouveau consensus ? / Human Transaltion and Natural Language Processing. Towards a new consensus, Venezia, Edizioni Ca’ Foscari, 2023.
GALISSON, Robert, Dictionnaire de compréhension et de production des expressions imagées, Paris, CLE International, 1988.
GIUSTI, Giuliana, « Inclusività della lingua italiana, nella lingua italiana : come e perché. Fondamenti teorici e proposte operative », DEP, n. 48, 2022.
GUERRINI, Marc, La démocratie inclusive : une alternative à la domination du marché et de l’État, Paris, Éditions du Passager Clandestin, 2008.
HADDAD, Raphaël, Manuel d’écriture inclusive, Paris, Mots-clés, 2016.
LAFORCADE, Agate, et al., « Artificial Intelligence and the Language of Law », JLL, numéro thématique, vol. 14, 2025.
LARROUY, Muriel, « Invention of Accessibility: French Urban Public Transportation Accessibility from 1975 to 2006 », Review of Disability Studies: An International Journal, n. 2, vol. 2, 2006, en ligne.
LESSARD, Michaël, ZACCOUR, Suzanne, Grammaire non sexiste de la langue française, Paris, Syllepse, 2017.
LO NOSTRO, Mariadomenica, MINERVINI, Rosaria, Il potere in-/es-cludente della lingua, L’Harmattan/AGA Editrice, 2024.
MARZI, Eleonora, « La traduction automatique neuronale et les biais de genre : le cas des noms de métiers entre l’italien et le français », Synergies Italie, n. 17, 2021 p. 19-36.
MATTIODA, Maria Margherita, et al., « L’intelligenza artificiale per la traduzione : orizzonti, pratiche e percorsi », MediAzioni, 2023, vol 39, p. 1-16.
MESCHONNIC, Henri, Poétique du traduire, Lagrasse, Éditions Verdier, 1999.
MICHARD, Claire, « Genre et sexe en linguistique : les analyses du masculin générique », Mots. Les langages du politique, n. 49, 1996, p. 29-47
MONTI, Johanna, « Questioni di genere in traduzione automatica », In De Meo, A., Di Pace, L., Manco, A. Al femminile, scritti linguistici in onore di Cristina Vallini, Florence, Franco Cesati editore, 2017, p. 411-431.
PARESH, Dave, « Fearful of bias, Google blocks gender-based pronouns from new AI tool ». Reuters, 2018, en ligne [consulté le 07 février 2021].
PAUGAM, Serge, L’exclusion : l’état des savoirs, Paris, La Découverte, 1996.
PIERGENTILI, Andrea, et al., « Gender neutralization fon an inclusive machine translation : from theoretical foundations to open challenges », Proceedings of the Firts Worksho on Gender-Inclusive Translation Technologies, 2023, P.71-83
PRUD’HOMME, Luc, et al., L’inclusion scolaire : ses fondements, ses acteurs et ses pratiques. Bruxelles, De Boeck Supérieur, 2016.
PRATES, Marcelo O. R et al., « Assessing gender bias in machine translation: A case study with Google Translate », Neural Computing and Applications, n. 32, vol. 10, 2020, p. 6363-6381, en ligne.
RABATEL, Alain, ROSIER, Laurence, « Les défis de l’écriture inclusive », Le discours et la langue, n.11, vol. 1, 2019, en ligne.
RAUS, Rachele, « Deep Learning e traduzione intralinguistica : riformulare i testi della pubblica amministrazione in modo inclusivo », Studi italiani di linguistica teorica e applicata, LII/3, 2024, p. 350-367.
RAUS, Rachele, TONTI, Michela, « Intelligence artificielle, corpus et diversité linguistique : enjeux et perspectives. Introduction », Languages, vol. 237/1, 2025, p. 7-20.
RUSSO, Chiara, « Intelligenze artificiali ma bias reali : Large Language Models, dati, e possibili mitigazioni », In AA.VV., Inclusione ed elaborazione del linguaggio naturale nell’era dell’intelligenza artificiale generativa, Milano, Ledizioni 2025, p. 217-225.
SAVOLDI, Beatrice et al., « A decade of gender bias in machine translation », Patterns, n. 6, vol. 6, 2025, en ligne.
STANOVSKY, Gabriel et al., « Evaluating Gender Bias in Machine Translation », Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Firenze, 2019, p. 1679-1684, en ligne.
SOFO, Giuseppe, « Le professeur est très intelligent /la prof est très attirante. Recongnizing and Reducing Gender Bias in Neural Machine Transaltion », In S. AMADORI et al., La traduction dans une perspective de genre. Enjeux, politiques, éditoriaux, Milano, LED 2022, p. 49-68.
TONTI, Michela, « ChatGPT et traduction intralinguistique inclusive : une étude pilote », De Europa, Special Issue, 2024 p. 83-107.
TONTI, Michela, « Les enjeux de la vulgarisation juridique française et européenne à l’aune de la reformulation intralinguistique de ChatGPT : des solutions prêtes-à-porter ? », Repères-Dorif, n. 32 Roma, 2025, en ligne.
VIENNOT, Éliane, Non, le masculin ne l’importe pas sur le féminin, Paris, Éditions iXe, 2014
VIENNOT, Éliane, Le langage inclusif : pourquoi, comment ? Paris, Éditions iXe, 2017.
VON FLOTOW, Louise, Gender in Translation, Amsterdam-Philadelphia, John Benjamins Publishing Company, 2022.
WISNIEWSKI, Guillaume, et al., « Biais de genre dans un système de traduction automatique neuronale : Une étude préliminaire », In P. DENIS, N. GRABAR, A. FRAISSE, R. CARDON, B. JACQUEMIN, E. KERGOSIEN et A. BALVET (Éds.), Traitement Automatique des Langues Naturelles, 2021, p. 11-25, en ligne.
YAGUELLO, Marina, Les mots et les femmes : essai d’approche sociolinguistique de la condition féminine, Saint-Germain, Payot, 1992.
YVON, François, « Évaluer, diagnostiquer et analyser la traduction automatique neuronale », In MAGGI, Ludovica, BORDES, Sarah, Intelligences pour la traduction. IA et interculturel : actions et interaction, John Benjamins Publishing Compagny, 2022, p. 315-332.
[1] La fragilité définitionnelle du concept d’inclusion, comme la définit Plaisance (2025), pourrait aussi engendrer un risque d’appauvrissement conceptuel, accentué par l’absence fréquente d’un cadre théorique explicite et solidement construit. Ceci menace la portée heuristique du concept, réduisant parfois son potentiel analytique à une formule passe-partout. C’est pourquoi nous insisterons sur la situationnalité du concept.
[2] Le concept d’écriture inclusive ne sera adopté que d’un point de vue binaire, c’est-à-dire de la dichotomie homme-femme (HADDAD 2016).
[3] Si le Traité de Rome faisait déjà référence à la justice sociale et à l’amélioration des conditions de vie, le terme d’inclusion en tant que tel n’a émergé qu’avec le développement des politiques sociales européennes dans les années 1990.
[4] Le document précise que la majorité de la population européenne a pour première langue une langue autre que le français ou l’anglais. Cette donnée démolinguistique renforce la nécessité d’adopter une approche multilingue et contextualisée de l’inclusivité, fondée sur la diversité réelle des langues et des cultures européennes.
[5] Pour aller plus loin, il vaudrait mieux tester les traducteurs automatiques dans leur manière de restituer des formes d’inclusivité implicite : par exemple, la valence inclusive contextuelle du pronom italien « chi ». Cette dernière n’est pas reconnue comme telle, ce qui entraîne une réduction de la performativité inclusive du texte traduit. Il s’agit là d’un indice supplémentaire de l’importance du positionnement linguistique et politique dans l’acte traductif, en particulier lorsqu’il s’inscrit dans un paradigme d’écriture inclusive. En l’absence d’une intervention humaine sensible aux enjeux de la langue, les outils automatiques tendent à reproduire des schémas normatifs, parfois reproducteurs de hiérarchies discursives implicites, et donc peu compatibles avec une approche de la traduction comme vecteur d’inclusion.
[6] À cet égard, on peut évoquer l’expérimentation du dispositif E-MIMIC (Empowering Multilingual Inclusive Communication), application fondée sur des réseaux neuronaux visant à rendre les textes administratifs plus inclusifs et qui a donné des résultats notables pour l’italien et le français, en exploitant par analogie les savoirs de la traduction automatique intralinguistique, toute en intégrant un apprentissage humans in the analytics loop et des critères linguistiques (RAUS 2024 ; TONTI 2024).
[7] Une conclusion comparable a été formulée par Tonti (2025) qui interroge, à partir d’une analyse des pratiques de reformulation en contexte juridique, l’accessibilité réelle des propositions vulgarisantes générées par un chatbot utilisé – à titre exploratoire – pour simplifier les formulations juridiques.
Per citare questo articolo:
Nicoletta ARMENTANO, « La traduction automatique inclusive dans le cadre institutionnel européen: une approche neuronale sous contraintes », Repères DoRiF, n. 34 – Inclusion, communication institutionnelle et traduction, DoRiF Università, Roma, aprile 2026, https://www.dorif.it/reperes/nicoletta-armentano-la-traduction-automatique-inclusive-dans-le-cadre-institutionnel-europeen-une-approche-neuronale-sous-contraintes/
ISSN 2281-3020
![]()
Quest’opera è distribuita con Licenza Creative Commons Attribuzione – Non commerciale – Non opere derivate 3.0 Italia.